LangSmith Evaluation Deep Dive
Preface
Video 1:Slides reviewing why evals are important hereVideo 2:Slides reviewing LangSmith primitives here
Summary
See here for an overview of evaluation: https://docs.smith.langchain.com/evaluation
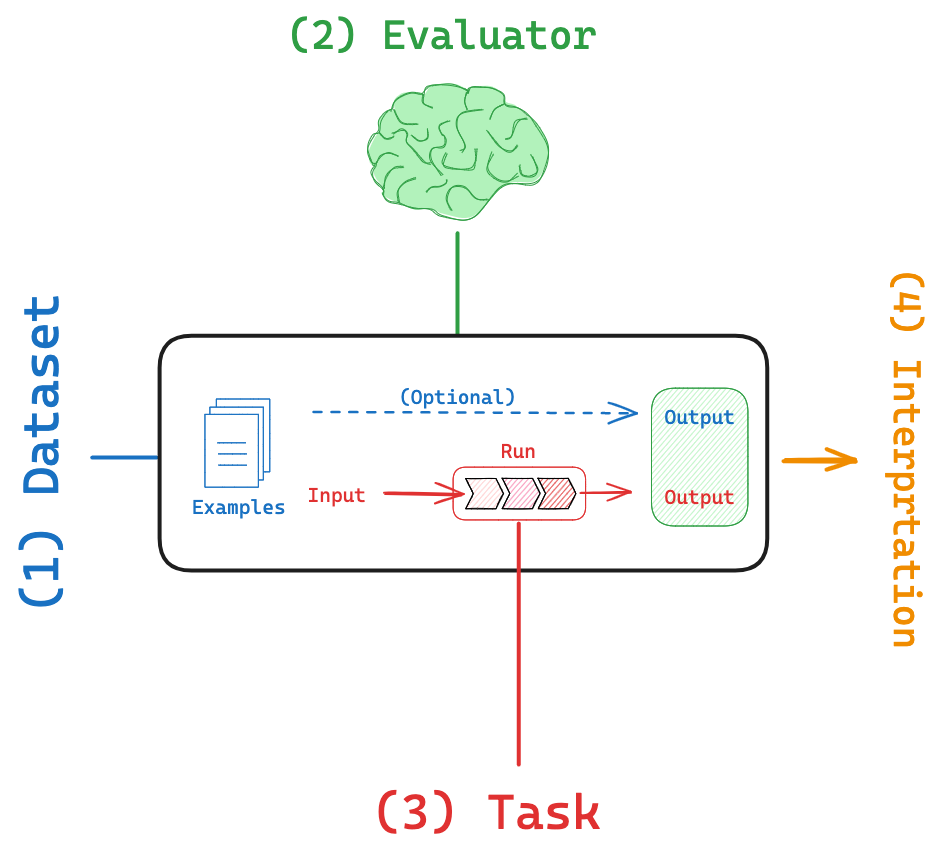
Enviornment
! pip install langsmith openai ollama
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true' # enables tracing
os.environ['LANGCHAIN_API_KEY'] = <your-api-key>
import os
os.environ['LANGCHAIN_PROJECT'] = 'Test'
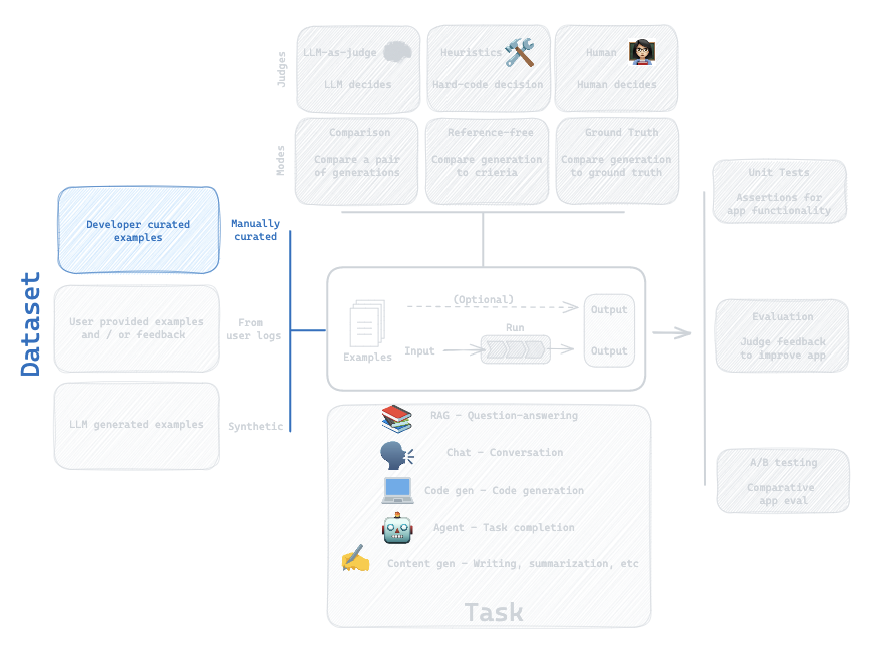
3. Dataset: Manually Curated
Question:
How can I build my own dataset?
Setup:
Let's build a dataset of question-answer pairs on this blog post about DBRX:
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
We'll build a Manually Curated dataset of input, output pairs:
import pandas as pd
# QA
inputs = [
"How many tokens was DBRX pre-trained on?",
"Is DBRX a MOE model and how many parameters does it have?",
"How many GPUs was DBRX trained on and what was the connectivity between GPUs?"
]
outputs = [
"DBRX was pre-trained on 12 trillion tokens of text and code data.",
"Yes, DBRX is a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters.",
"DBRX was trained on 3072 NVIDIA H100s connected by 3.2Tbps Infiniband"
]
# Dataset
qa_pairs = [{"question": q, "answer": a} for q, a in zip(inputs, outputs)]
df = pd.DataFrame(qa_pairs)
# Write to csv
csv_path = "/Users/rlm/Desktop/DBRX_eval.csv"
df.to_csv(csv_path, index=False)
LangSmith SDK docs:
from langsmith import Client
client = Client()
dataset_name = "DBRX"
# Store
dataset = client.create_dataset(
dataset_name=dataset_name,
description="QA pairs about DBRX model.",
)
client.create_examples(
inputs=[{"question": q} for q in inputs],
outputs=[{"answer": a} for a in outputs],
dataset_id=dataset.id,
)
Update dataset
new_questions = [
"What is the context window of DBRX Instruct?",
]
new_answers = [
"DBRX Instruct was trained with up to a 32K token context window.",
]
# See updated version in the UI
client.create_examples(
inputs=[{"question": q} for q in new_questions],
outputs=[{"answer": a} for a in new_answers],
dataset_id=dataset.id,
)
We can also create a dataset directly from a csv with the LangSmith UI.
LangSmith UI docs:
https://docs.smith.langchain.com/evaluation/faq/manage-datasets
4. Dataset: From User Logs
Question:
How can I save user logs as a dataset for future testing?
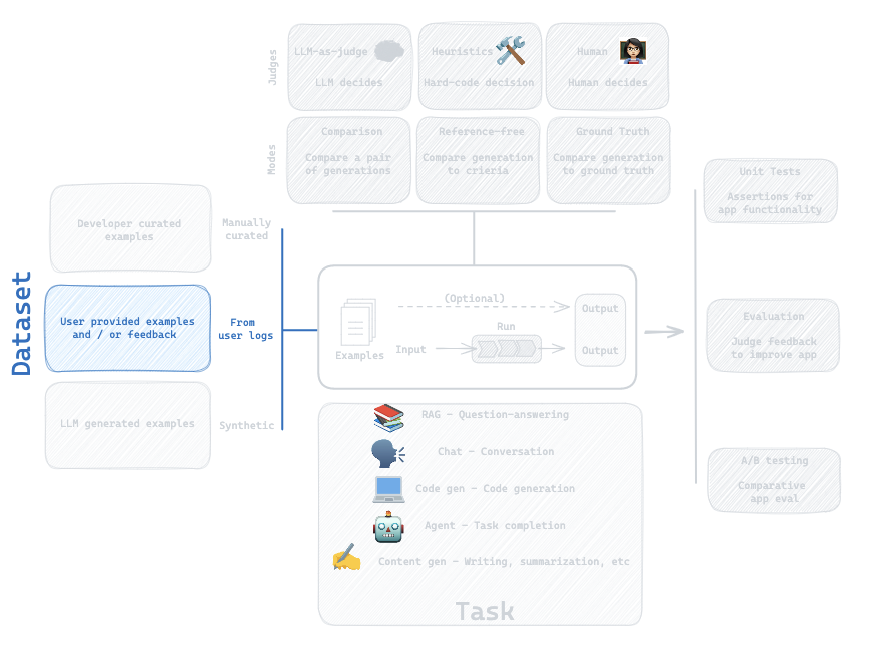
# Create a new project where user question are logged
import os
os.environ['LANGCHAIN_PROJECT'] = 'DBRX'
# Load blog post
import requests
from bs4 import BeautifulSoup
url = 'https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
text = [p.text for p in soup.find_all('p')]
full_text = '\n'.join(text)
# OpenAI API
import openai
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(openai.Client())
def answer_dbrx_question_oai(inputs: dict) -> dict:
"""
Generates answers to user questions based on a provided website text using OpenAI API.
Parameters:
inputs (dict): A dictionary with a single key 'question', representing the user's question as a string.
Returns:
dict: A dictionary with a single key 'output', containing the generated answer as a string.
"""
# System prompt
system_msg = f"Answer user questions in 2-3 sentences about this context: \n\n\n {full_text}"
# Pass in website text
messages = [{"role": "system", "content": system_msg},
{"role": "user", "content": inputs["question"]}]
# Call OpenAI
response = openai_client.chat.completions.create(messages=messages, model="gpt-3.5-turbo")
# Response in output dict
return {"answer": response.dict()['choices'][0]['message']['content']}
# User question example
answer_dbrx_question_oai({"question":"What are the main differences in training efficiency between MPT-7B vs DBRX?"})
# User question example
answer_dbrx_question_oai({"question":"How many tokens was DBRX pre-trained on?"})
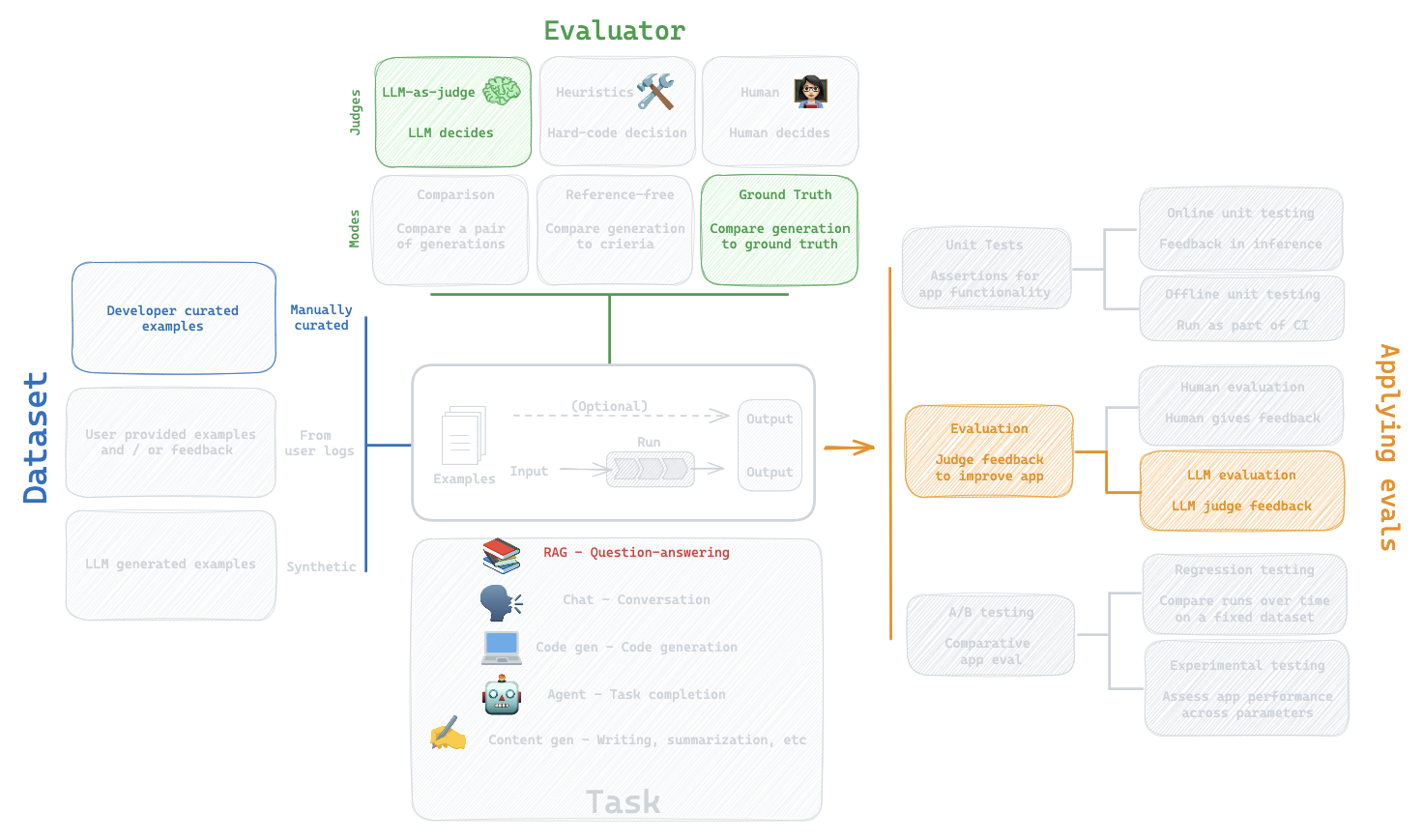
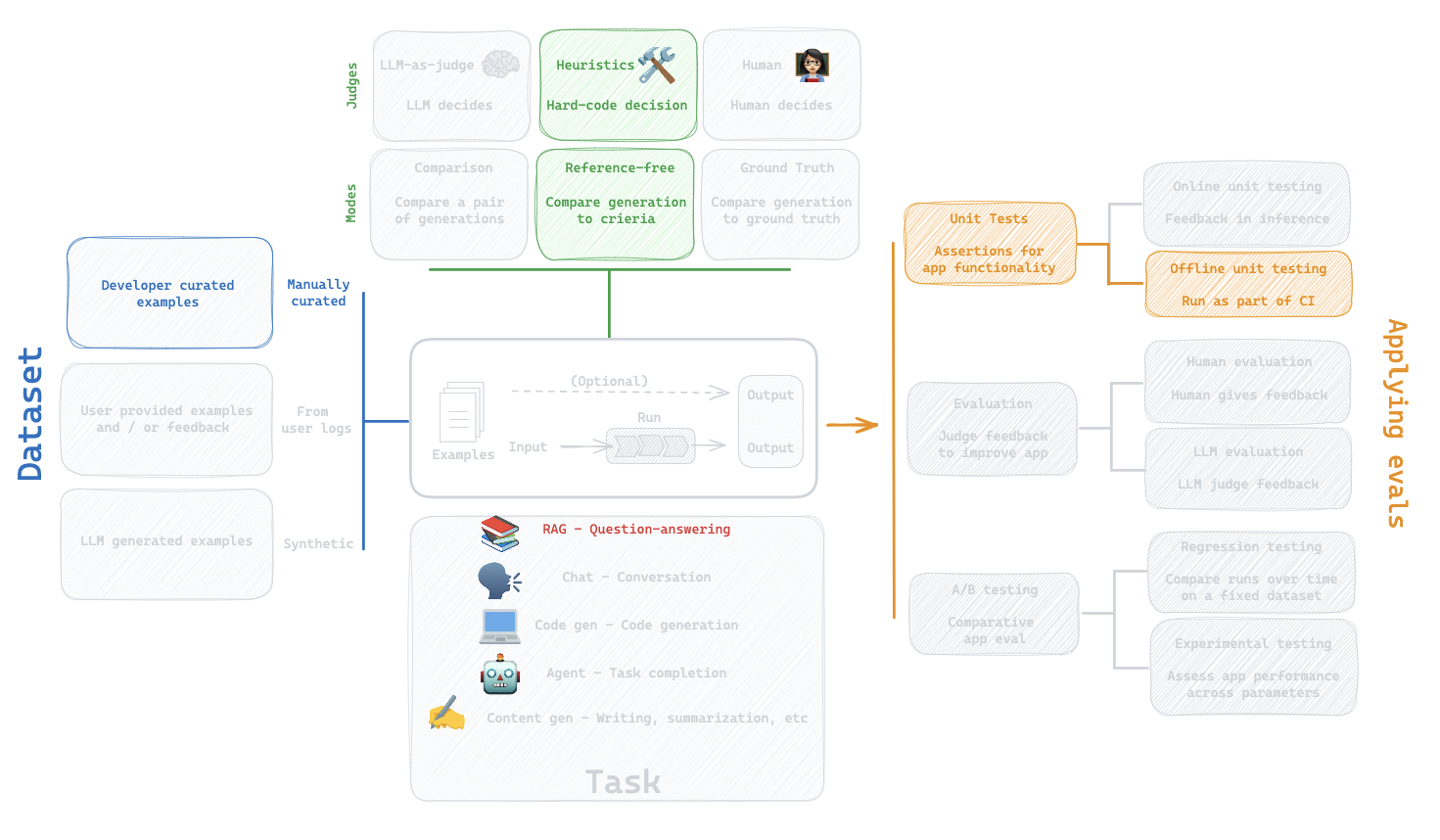
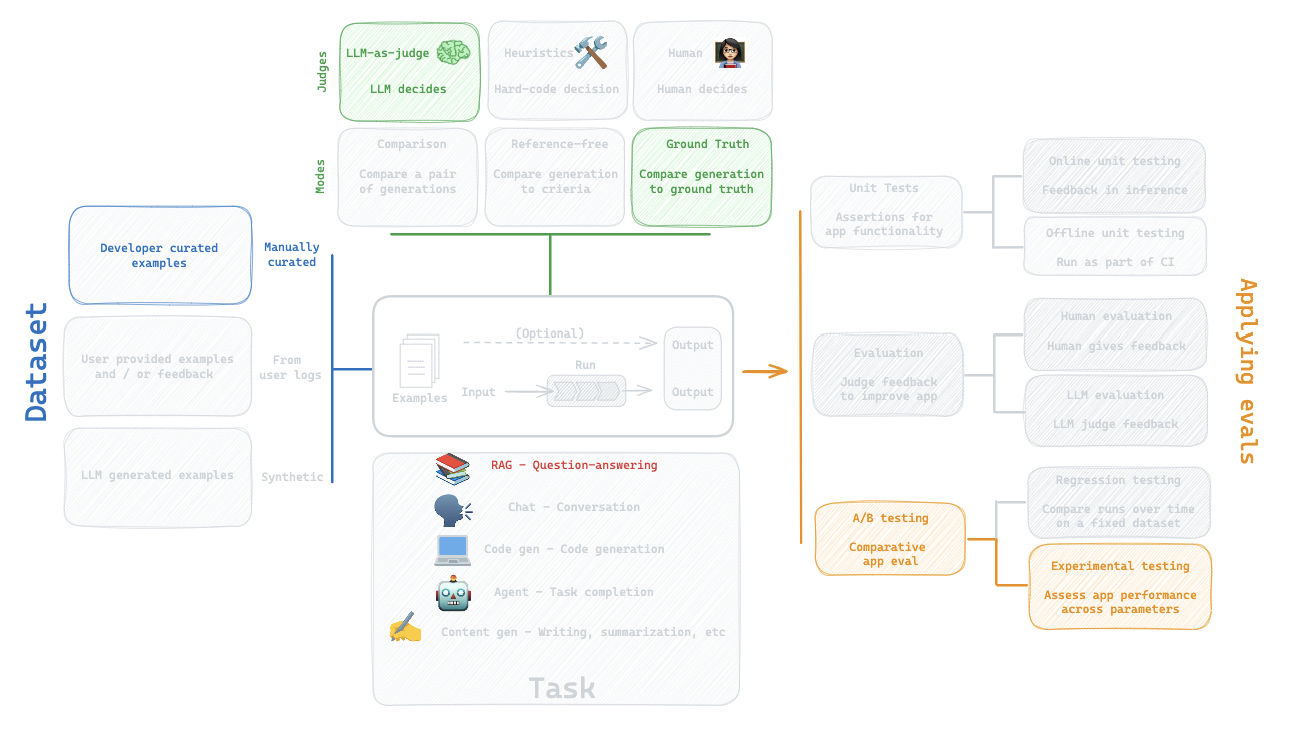
5. LLM-as-Judge: Built-in evaluator
Question:
How can I evaluate the my LLM against my dataset?
Evaluation flow
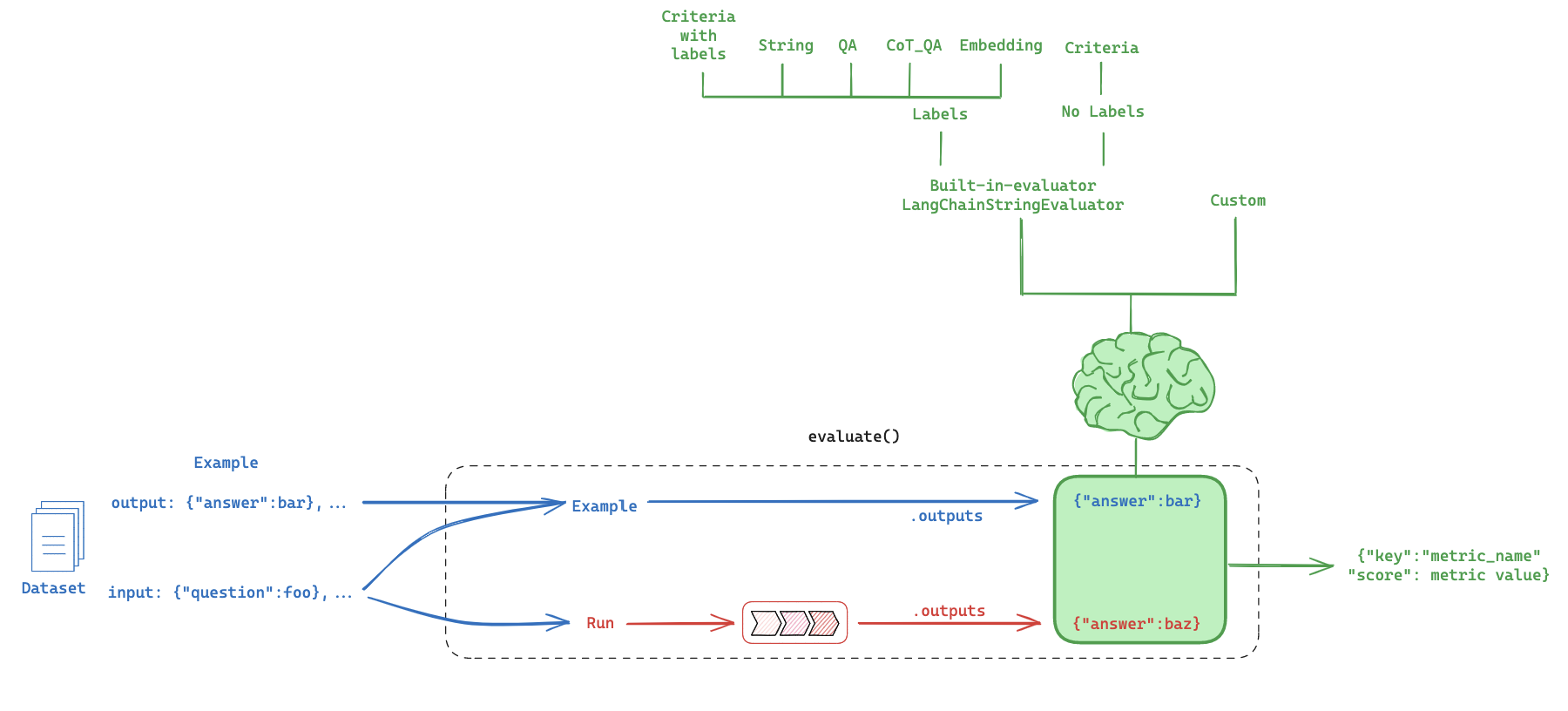
Built-in evaluator
https://docs.smith.langchain.com/evaluation/faq/evaluator-implementations
CoT_qa
Use chain of thought "reasoning" before determining a final verdict
from langsmith.evaluation import evaluate, LangChainStringEvaluator
# Evaluators
qa_evalulator = [LangChainStringEvaluator("cot_qa")]
dataset_name = "DBRX"
experiment_results = evaluate(
answer_dbrx_question_oai,
data=dataset_name,
evaluators=qa_evalulator,
experiment_prefix="test-dbrx-qa-oai",
# Any experiment metadata can be specified here
metadata={
"variant": "stuff website context into gpt-3.5-turbo",
},
)
What did we do?
6. Custom evaluator
Question:
How can I define my own custom evaluator?
Let's say we want to define a simple assertion that an answer is actually generated.
from langsmith.schemas import Run, Example
def is_answered(run: Run, example: Example) -> dict:
# Get outputs
student_answer = run.outputs.get("answer")
# Check if the student_answer is an empty string
if not student_answer:
return {"key": "is_answered" , "score": 0}
else:
return {"key": "is_answered" , "score": 1}
# Evaluators
qa_evalulator = [is_answered]
dataset_name = "DBRX"
# Run
experiment_results = evaluate(
answer_dbrx_question_oai,
data=dataset_name,
evaluators=qa_evalulator,
experiment_prefix="test-dbrx-qa-custom-eval-is-answered",
# Any experiment metadata can be specified here
metadata={
"variant": "stuff website context into gpt-3.5-turbo",
},
)
7. Comparison
Question:
How does Mistral-7b running locally compare to GPT-3.5-turbo for question-answering?
Setup:
https://github.com/ollama/ollama-python
ollama pull mistral
Instrument Ollama calls with LangSmith:
https://docs.smith.langchain.com/cookbook/tracing-examples/traceable#using-the-decorator
# Mistral
import ollama
from langsmith.run_helpers import traceable
@traceable(run_type="llm")
def call_ollama(messages, model: str):
stream = ollama.chat(messages=messages, model='mistral', stream=True)
response = ''
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
response = response + chunk['message']['content']
return response
def answer_dbrx_question_mistral(inputs: dict) -> dict:
"""
Generates answers to user questions based on a provided website text using Ollama serving Mistral locally.
Parameters:
inputs (dict): A dictionary with a single key 'question', representing the user's question as a string.
Returns:
dict: A dictionary with a single key 'output', containing the generated answer as a string.
"""
# System prompt
system_msg = f"Answer user questions about this context: \n\n\n {full_text}"
# Pass in website text
messages = [{"role": "system", "content": system_msg},
{"role": "user", "content": f'Answer the question in 2-3 sentences {inputs["question"]}' }]
# Call Mistral
response = call_ollama(messages, model="mistral")
# Response in output dict
return {"answer": response}
result = answer_dbrx_question_mistral({"question":"What are the main differences in training efficiency between MPT-7B vs DBRX?"})
What are we doing?
# Evaluators
qa_evalulator = [LangChainStringEvaluator("cot_qa")]
dataset_name = "DBRX"
experiment_results = evaluate(
answer_dbrx_question_mistral,
data=dataset_name,
evaluators=qa_evalulator,
experiment_prefix="test-dbrx-qa-mistral",
# Any experiment metadata can be specified here
metadata={
"variant": "stuff website context into mistral",
},
)
Use comparison view to inspect results.
8. Experiment on datasets from the prompt playground (no code)
We've showed various ways to run evals using the SDK.
But sometimes I want to do more rapid testing.
For this I can use the LangSmith prompt hub directly:
https://docs.smith.langchain.com/evaluation/faq/experiments-app
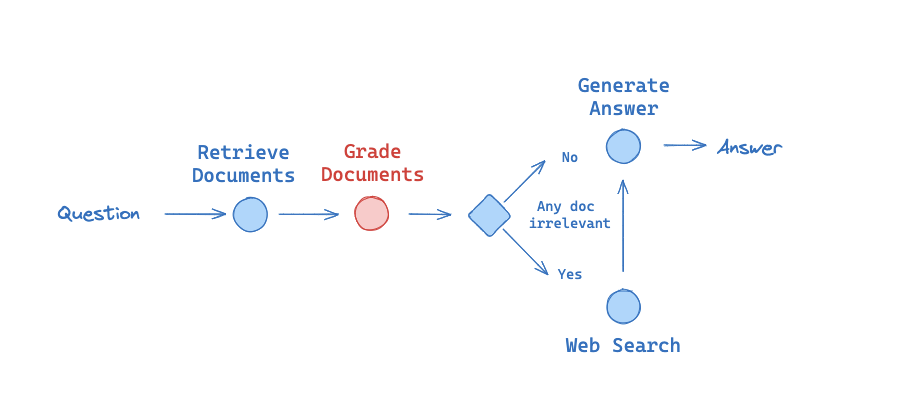
Here is a problem I've worked on recently:
I want to grade documents in a RAG chain that takes as input: (1) A document and (2) A question.
And returns: (3) JSON with score yes or no that tells me if the documents are related to a question.
See notebooks here.
Question:
How do different LLMs perform at instruction following to produce a JSON output?
First, I build a dataset of test examples:
# Define a dataset
import pandas as pd
# relevance check
inputs = [
{"question":"agent memory","doc_txt":"agent memory has two types: short and long term"},
{"question":"hallucinations","doc_txt":"DBRX was pretrained on 12T tokens"},
{"question":"DBRX content window","doc_txt":"DBRX has a 32K token context window"},
]
outputs = [
"yes",
"no",
"yes"
]
from langsmith import Client
client = Client()
dataset_name = "Relevance_grade"
# Store
dataset = client.create_dataset(
dataset_name=dataset_name,
description="Testing relevance grading.",
)
client.create_examples(
inputs=inputs,
outputs=[{"answer": a} for a in outputs],
dataset_id=dataset.id,
)
Test prompt in the Prompt Hub.
SYSTEM
You are a grader assessing relevance of a retrieved document to a user question. It does not need to be a stringent test. The goal is to filter out erroneous retrievals. If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. Provide the binary score as a JSON with a single key 'score' and no premable or explaination.
HUMAN
Question: {question}
Document: {doc_txt}
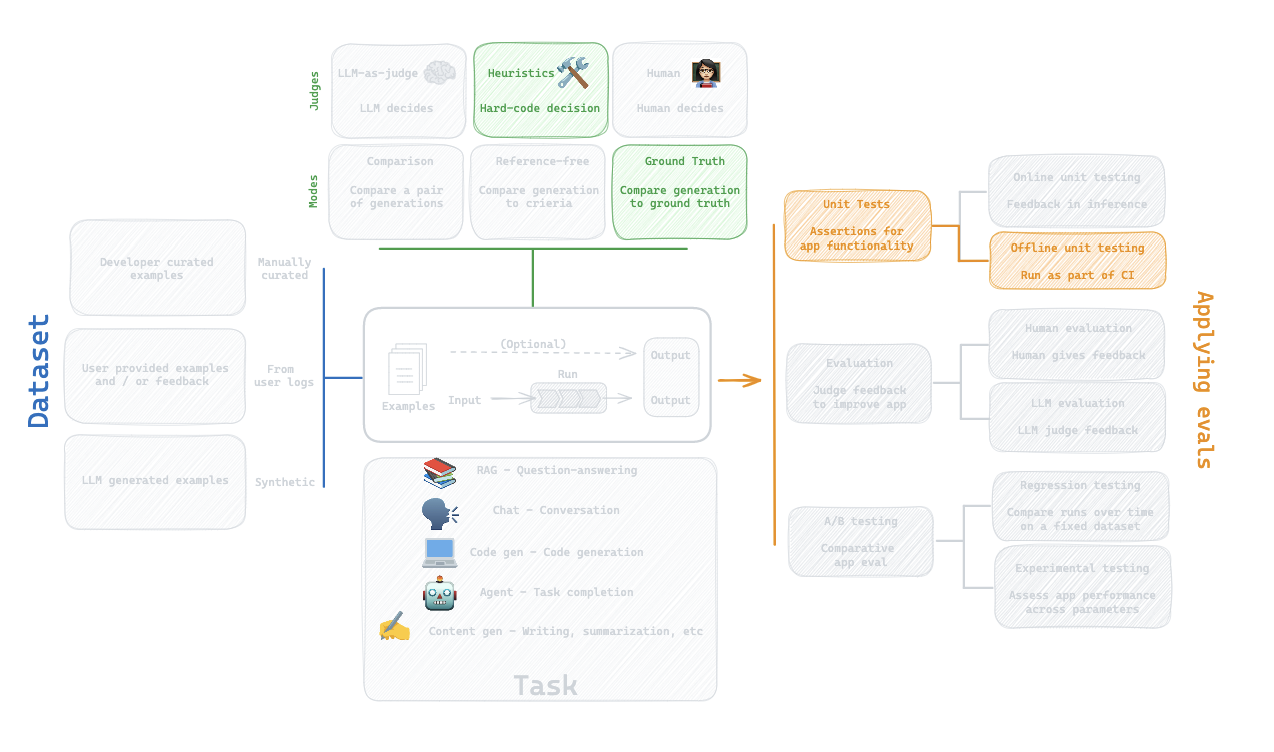
9. Attach evaluators to datasets (no code)
From part 8, we:
(1) Set up a dataset of test cases for document grading
(2) Ran experiments from the prompt hub
(3) Manually reviewed them
But, we can go one step further:
We can attach an LLM evaluator to our dataset.
This is automatically applied for every experiment.
Grade prompt:
You are a grader. You will be shown:
(1) Submission: a student submission for a JSON string
(2) Reference: the ground truth value expected in the JSON string
The student is producing a JSON with a single key "score" to indicate whether doc_text is relevant to question for this input:
[Input]: {input}
Grade the student as correct if that the student submission is valid JSON (or a JSON string) and contains the Reference value. If the student submission contains a preamble of text "e.g., 'sure, here is the JSON'" then score that as incorrect because we only want to JSON returned.
[BEGIN DATA]
***
[Submission]: {output}
***
[Reference]: {reference}
***
[END DATA]
10. Instrumenting Unit Tests
Unit tests are often simple assertions that are run as part of CI.
Example:
I've some recent work on code generation (e.g., see this example).
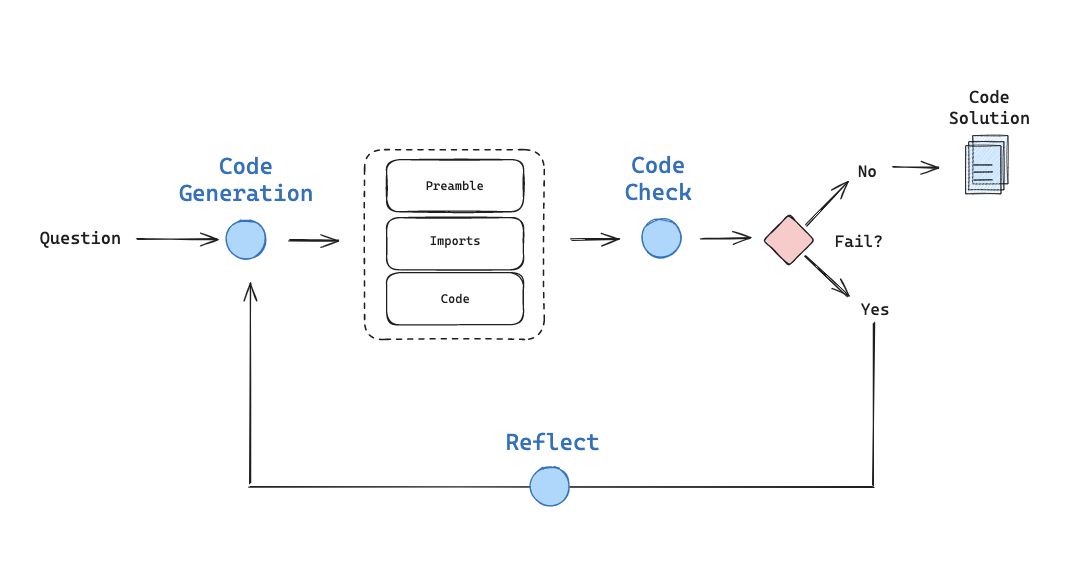
I use function calling to produce a solution with prefix, imports, and code blocks.
Question:
How can I instrument unit tests that check whether the imports and code blocks execute?
We'll create an example app, my_app/main.py, that generate a solution with prefix, imports, and code blocks.
Set up example app and test -
# my_app/main.py
# tests/test_my_app.py
Run -
export PYTHONPATH="/Users/rlm/Desktop/Code/langsmith-cookbook:$PYTHONPATH"
pytest
See results logged to LangSmith.
Documentation:
https://docs.smith.langchain.com/evaluation/faq/unit-testing
11. Summary Evaluators
We previously talked about using retrieval grading as part of RAG:
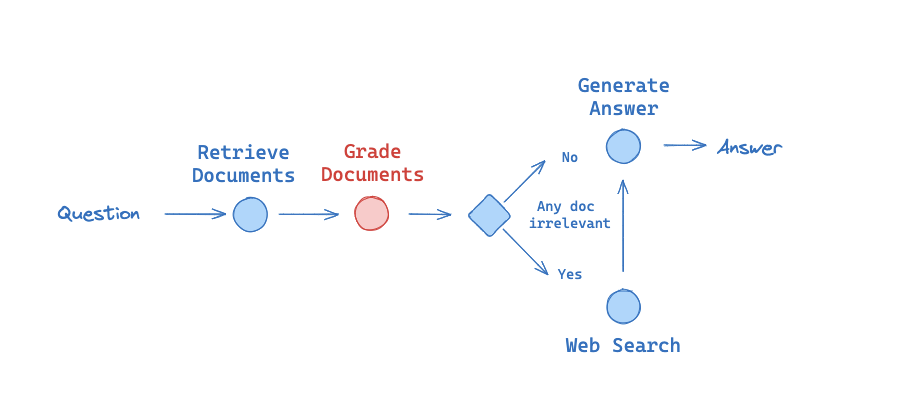
In short, we use an LLM to grader whether a document is relevant to input question.
This returns a binary yes or no.
We built an eval set and ground truth is a binary yes or no for each example:
https://smith.langchain.com/public/ad300ffb-8bf5-450a-9c26-1b34481fb709/d
Question:
How can I create a custom metric to summarize performance on this dataset?
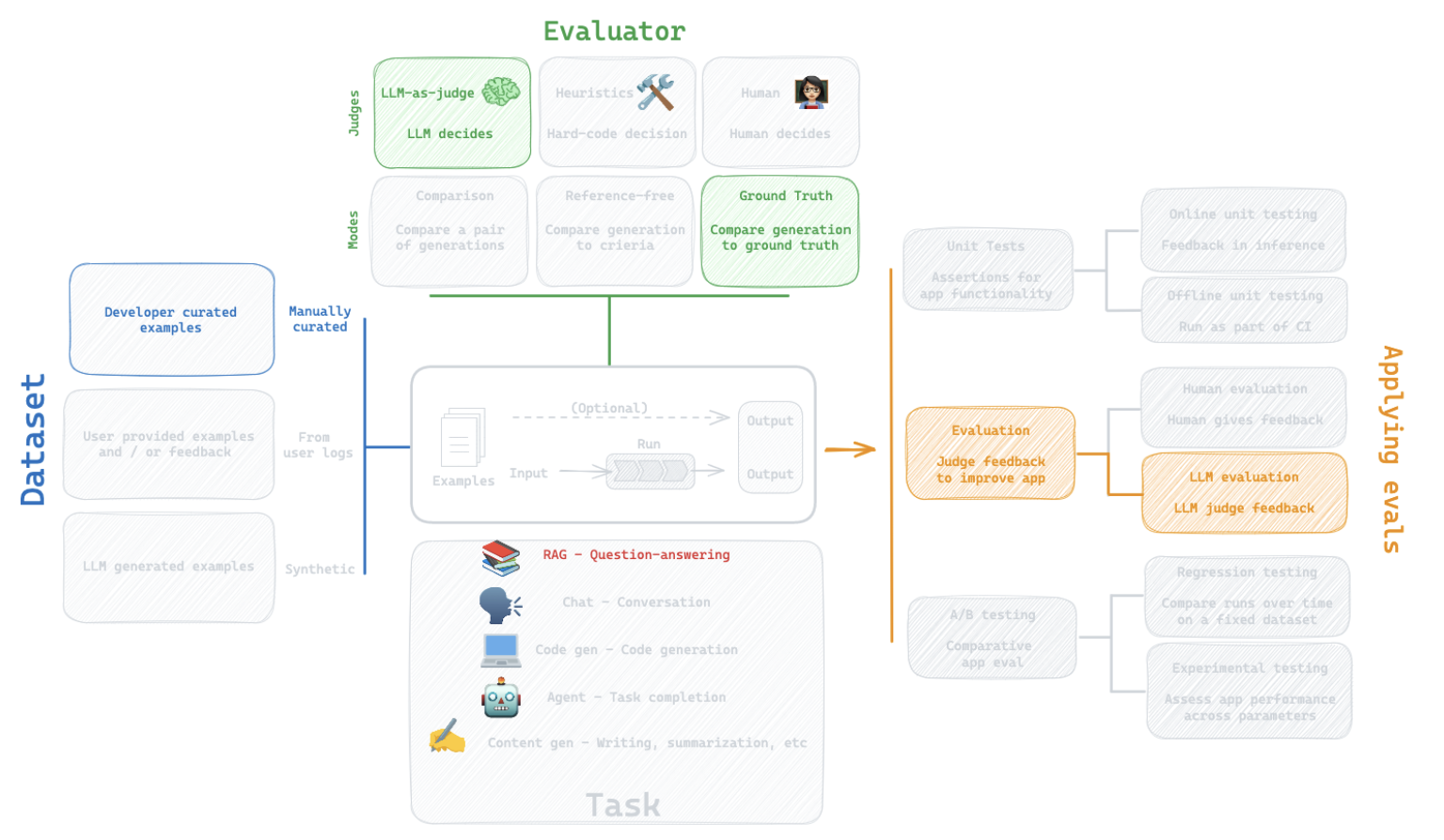
First, let's set up the two chains we want to compare:
### OpenAI Grader
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader_oai = grade_prompt | structured_llm_grader
def predict_oai(inputs: dict) -> dict:
# Returns pydantic object
grade = retrieval_grader_oai.invoke({"question": inputs["question"], "document": inputs["doc_txt"]})
return {"grade":grade.score}
### Mistral Grader
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import JsonOutputParser
# LLM
llm = ChatOllama(model="mistral", format="json", temperature=0)
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {document} \n\n
Here is the user question: {question} \n
If the document contains keywords related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question. \n
Provide the binary score as a JSON with a single key 'score' and no premable or explaination.""",
input_variables=["question", "document"],
)
retrieval_grader_mistral = prompt | llm | JsonOutputParser()
def predict_mistral(inputs: dict) -> dict:
# Returns JSON
grade = retrieval_grader_mistral.invoke({"question": inputs["question"], "document": inputs["doc_txt"]})
return {"grade":grade['score']}
Documentation:
https://docs.smith.langchain.com/evaluation/faq/custom-evaluators#summary-evaluators
We can define a custom summary metric over the dataset.
Precision and Recall are common metrics to evaluate a binary clasification:
Precision: True positives (TP) / All positives (TP + False Positives (FP)).Recall:TP/ All samples that should have been identified as positive
F1 considers both the precision and the recall of the test to compute the score:
F1score is the harmonic mean of precision and recall, and it reaches its best value at 1
from typing import List
from langsmith.schemas import Example, Run
from langsmith.evaluation import evaluate
def f1_score_summary_evaluator(runs: List[Run], examples: List[Example]) -> dict:
"""
Evaluates the F1 score for a list of runs against a set of examples.
The function iterates through paired runs and examples, comparing the output
of each run (`run.outputs["grade"]`) with the expected output in the example
(`example.outputs["answer"]`). It calculates the true positives, false positives,
and false negatives based on these comparisons to compute the F1 score of the predictions.
Parameters:
- runs (List[Run]): A list of run objects, where each run contains an output that is a prediction.
- examples (List[Example]): A list of example objects, where each example contains an output that is the expected answer.
Returns:
- dict: A dictionary with a single key-value pair where the key is "f1_score" and the value
"""
# Default values
true_positives = 0
false_positives = 0
false_negatives = 0
# Iterate through samples
for run, example in zip(runs, examples):
reference = example.outputs["answer"]
prediction = run.outputs["grade"]
if reference and prediction == reference:
true_positives += 1
elif prediction and not reference:
false_positives += 1
elif not prediction and reference:
false_negatives += 1
if true_positives == 0:
return {"key": "f1_score", "score": 0.0}
# Compute F1 score
precision = true_positives / (true_positives + false_positives)
recall = true_positives / (true_positives + false_negatives)
f1_score = 2 * (precision * recall) / (precision + recall)
return {"key": "f1_score", "score": f1_score}
evaluate(
predict_mistral,
data="Relevance_grade",
summary_evaluators=[f1_score_summary_evaluator],
experiment_prefix="test-score-mistral",
# Any experiment metadata can be specified here
metadata={
"model": "mistral",
},
)
View the evaluation results for experiment: 'test-score-mistral-c288bf9f' at:
https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/1627c2dc-8207-44a1-86a3-bc7e23bd9777/compare?selectedSessions=f6a22a99-5e13-47d5-916a-cdd6b1a0ea38
0it [00:00, ?it/s]
<ExperimentResults test-score-mistral-c288bf9f>
evaluate(
predict_oai,
data="Relevance_grade",
summary_evaluators=[f1_score_summary_evaluator],
experiment_prefix="test-score-oai",
# Any experiment metadata can be specified here
metadata={
"model": "oai",
},
)
View the evaluation results for experiment: 'test-score-oai-dccbb67b' at:
https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/1627c2dc-8207-44a1-86a3-bc7e23bd9777/compare?selectedSessions=1614d57e-3152-41a9-98e2-ba23c12a0439
0it [00:00, ?it/s]
<ExperimentResults test-score-oai-dccbb67b>
12-14. Evaluating RAG
See our RAG guide.
# Evaluators
qa_evalulator = [LangChainStringEvaluator("cot_qa")]
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer,
data=dataset_name,
evaluators=qa_evalulator,
experiment_prefix="rag-qa-oai",
# Any experiment metadata can be specified here
metadata={
"variant": "LCEL context, gpt-3.5-turbo",
},
)
View the evaluation results for experiment: 'rag-qa-oai-166e3567' at:
https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/368734fb-7c14-4e1f-b91a-50d52cb58a07/compare?selectedSessions=bc8c1195-1722-4ec9-9b18-45b76c648717
0it [00:00, ?it/s]
15. Regression testing
Previously, we talked about various types of RAG evaluations.
Question:
How can I assess whether a new LLM (e.g., phi3), can I be used in my RAG chain?
For this, regression testing is highly useful.
It lets us easily pinpoint changes in performance in our eval set across model versions.
First, define an eval set:
import os
os.environ['LANGCHAIN_PROJECT'] = 'RAG_bot_langsmith_online_eval'
from langsmith import Client
# QA
inputs = [
"My LCEL map contains the key 'question'. What is the difference between using itemgetter('question'), lambda x: x['question'], and x.get('question')?",
"How can I make the output of my LCEL chain a string?",
"How can I run two LCEL chains in parallel and write their output to a map?"
]
outputs = [
"Itemgetter can be used as shorthand to extract specific keys from the map. In the context of a map operation, the lambda function is applied to each element in the input map and the function returns the value associated with the key 'question'. (get) is safer for accessing values in a dictionary because it handles the case where the key might not exist.",
"Use StrOutputParser. from langchain_openai import ChatOpenAI; from langchain_core.prompts import ChatPromptTemplate; from langchain_core.output_parsers import StrOutputParser; prompt = ChatPromptTemplate.from_template('Tell me a short joke about {topic}'); model = ChatOpenAI(model='gpt-3.5-turbo') #gpt-4 or other LLMs can be used here; output_parser = StrOutputParser(); chain = prompt | model | output_parser",
"We can use RunnableParallel. For example: from langchain_core.prompts import ChatPromptTemplate; from langchain_core.runnables import RunnableParallel; from langchain_openai import ChatOpenAI; model = ChatOpenAI(); joke_chain = ChatPromptTemplate.from_template('tell me a joke about {topic}') | model; poem_chain = (ChatPromptTemplate.from_template('write a 2-line poem about {topic}') | model); map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain); map_chain.invoke({'topic': 'bear'})"
]
qa_pairs = [{"question": q, "answer": a} for q, a in zip(inputs, outputs)]
# Create dataset
client = Client()
dataset_name = "RAG_QA_LCEL"
dataset = client.create_dataset(
dataset_name=dataset_name,
description="QA pairs about LCEL.",
)
client.create_examples(
inputs=[{"question": q} for q in inputs],
outputs=[{"answer": a} for a in outputs],
dataset_id=dataset.id,
)
RAG chain:
### INDEX
from bs4 import BeautifulSoup as Soup
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
# Load
url = "https://python.langchain.com/docs/expression_language/"
loader = RecursiveUrlLoader(url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text)
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2500, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embed
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Index
retriever = vectorstore.as_retriever()
### RAG
import openai
from langsmith import traceable
from langsmith.wrappers import wrap_openai
from langchain.prompts import PromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.output_parsers import StrOutputParser
class RagBot:
def __init__(self, retriever, provider: str = "openai", model: str = "gpt-4-0125-preview"):
self._retriever = retriever
self._provider = provider
self._model = model
if provider == "openai":
self._client = wrap_openai(openai.Client())
elif provider == "ollama":
self._client = ChatOllama(model=model, temperature=0)
def retrieve_docs(self, question):
return self._retriever.invoke(question)
@traceable()
def get_answer(self, question: str):
similar = self.retrieve_docs(question)
if self._provider == "openai":
"OpenAI RAG"
response = self._client.chat.completions.create(
model=self._model,
messages=[
{
"role": "system",
"content": "You are a helpful AI code assistant with expertise in LCEL.\n"
" Use the following docs to produce a concise code solution to the user question.\n"
" Use three sentences maximum and keep the answer concise. \n"
f"## Docs\n\n{similar}",
},
{"role": "user", "content": question},
],
)
response_str = response.choices[0].message.content
elif self._provider == "ollama":
"Ollama RAG"
prompt = PromptTemplate(
template="""You are a helpful AI code assistant with expertise in LCEL.
Use the following docs to produce a concise code solution to the user question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer: """,
input_variables=["question", "context"],
)
rag_chain = prompt | self._client | StrOutputParser()
response_str = rag_chain.invoke({"context":similar,"question":question})
return {
"answer": response_str,
"contexts": [str(doc) for doc in similar],
}
def predict_rag_answer_oai(example: dict):
"""Use this for answer evaluation"""
rag_bot = RagBot(retriever,provider="openai",model="gpt-4-0125-preview")
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"]}
def predict_rag_answer_llama3(example: dict):
"""Use this for answer evaluation"""
rag_bot = RagBot(retriever,provider="ollama",model="llama3")
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"]}
def predict_rag_answer_phi3(example: dict):
"""Use this for answer evaluation"""
rag_bot = RagBot(retriever,provider="ollama",model="phi3")
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"]}
Define evaluator:
from langsmith.evaluation import LangChainStringEvaluator, evaluate
answer_evaluator = LangChainStringEvaluator(
"labeled_score_string",
config={
"criteria": {
"accuracy": """Is the Assistant's Answer grounded in and similar to the Ground Truth answer? A score of [[1]] means that the
Assistant answer is not at all grounded in and similar to the Ground Truth answer. A score of [[5]] means that the Assistant
answer contains some information that is grounded in and similar to the Ground Truth answer. A score of [[10]] means that the
Assistant answer is fully grounded in and similar to the Ground Truth answer."""
},
# If you want the score to be saved on a scale from 0 to 1
"normalize_by": 10,
},
prepare_data=lambda run, example: {
"prediction": run.outputs["answer"],
"reference": example.outputs["answer"],
"input": example.inputs["question"],
}
)
from langsmith.evaluation import LangChainStringEvaluator, evaluate
dataset_name = "RAG_QA_LCEL"
experiment_results = evaluate(
predict_rag_answer_oai,
data=dataset_name,
evaluators=[answer_evaluator],
experiment_prefix="rag-qa-gpt4-0125",
metadata={"variant": "LCEL context, gpt-4-0125-preview"},
)
View the evaluation results for experiment: 'rag-qa-gpt4-0125-6b799ce4' at:
https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/185fcfba-a9cb-4868-9904-86644881d363/compare?selectedSessions=98981d76-b10f-4856-b6be-ed86f035b34c
0it [00:00, ?it/s]
experiment_results = evaluate(
predict_rag_answer_llama3,
data=dataset_name,
evaluators=[answer_evaluator],
experiment_prefix="rag-qa-llama3",
metadata={"variant": "LCEL context, gpt-4-0125-preview"},
)
View the evaluation results for experiment: 'rag-qa-llama3-ad040c84' at:
https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/185fcfba-a9cb-4868-9904-86644881d363/compare?selectedSessions=c78dc2a7-b99c-48bf-9613-70fe53dae303
0it [00:00, ?it/s]
experiment_results = evaluate(
predict_rag_answer_phi3,
data=dataset_name,
evaluators=[answer_evaluator],
experiment_prefix="rag-qa-phi3",
metadata={"variant": "LCEL context, phi3"},
)
View the evaluation results for experiment: 'rag-qa-phi3-d8ebf147' at:
https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/185fcfba-a9cb-4868-9904-86644881d363/compare?selectedSessions=a71ffea1-b2b2-4e3b-963f-5f31de646083
0it [00:00, ?it/s]
17. Online Evaluators
Sometimes we want to evaluate generations as they are logged to a project.
# Test our RAG bot
rag_bot = RagBot(retriever,provider="openai",model="gpt-4-0125-preview")
response = rag_bot.get_answer("How to define an RAG chain in LCEL?")