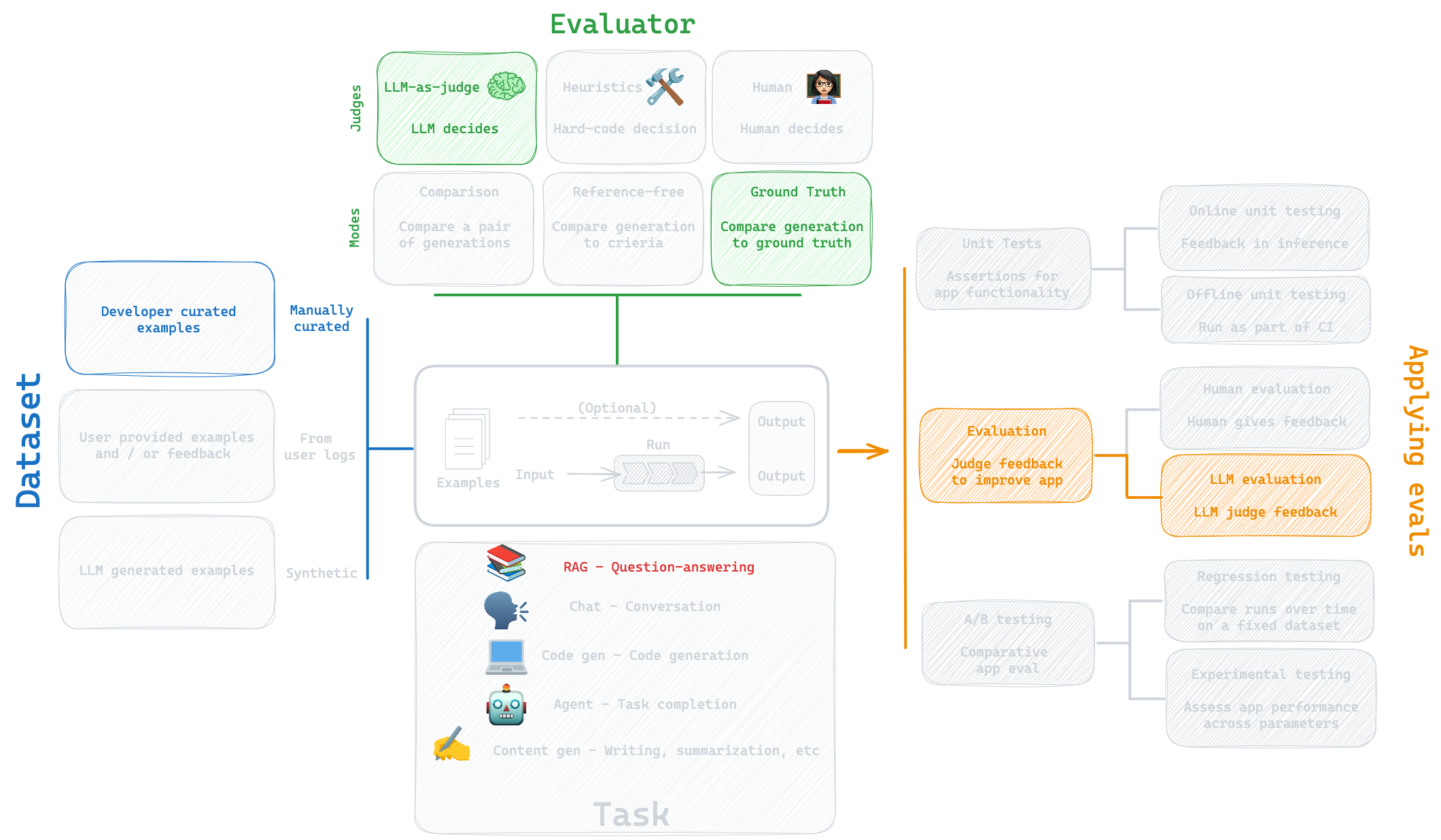
RAG Evaluation
![]()
RAG (Retrieval Augmented Generation) is one of the most popular techniques for building applications with LLMs.
For an in-depth review, see our RAG series of notebooks and videos here).
Types of RAG eval
There are at least 4 types of RAG eval that users of typically interested in (here, <> means "compared against"):
- Response <> reference answer: metrics like correctness measure "how similar/correct is the answer, relative to a ground-truth label"
- Response <> input: metrics like answer relevance, helpfulness, etc. measure "how well does the generated response address the initial user input"
- Response <> retrieved docs: metrics like faithfulness, hallucinations, etc. measure "to what extent does the generated response agree with the retrieved context"
- Retrieved docs <> input: metrics like score @ k, mean reciprocal rank, NDCG, etc. measure "how good are my retrieved results for this query"
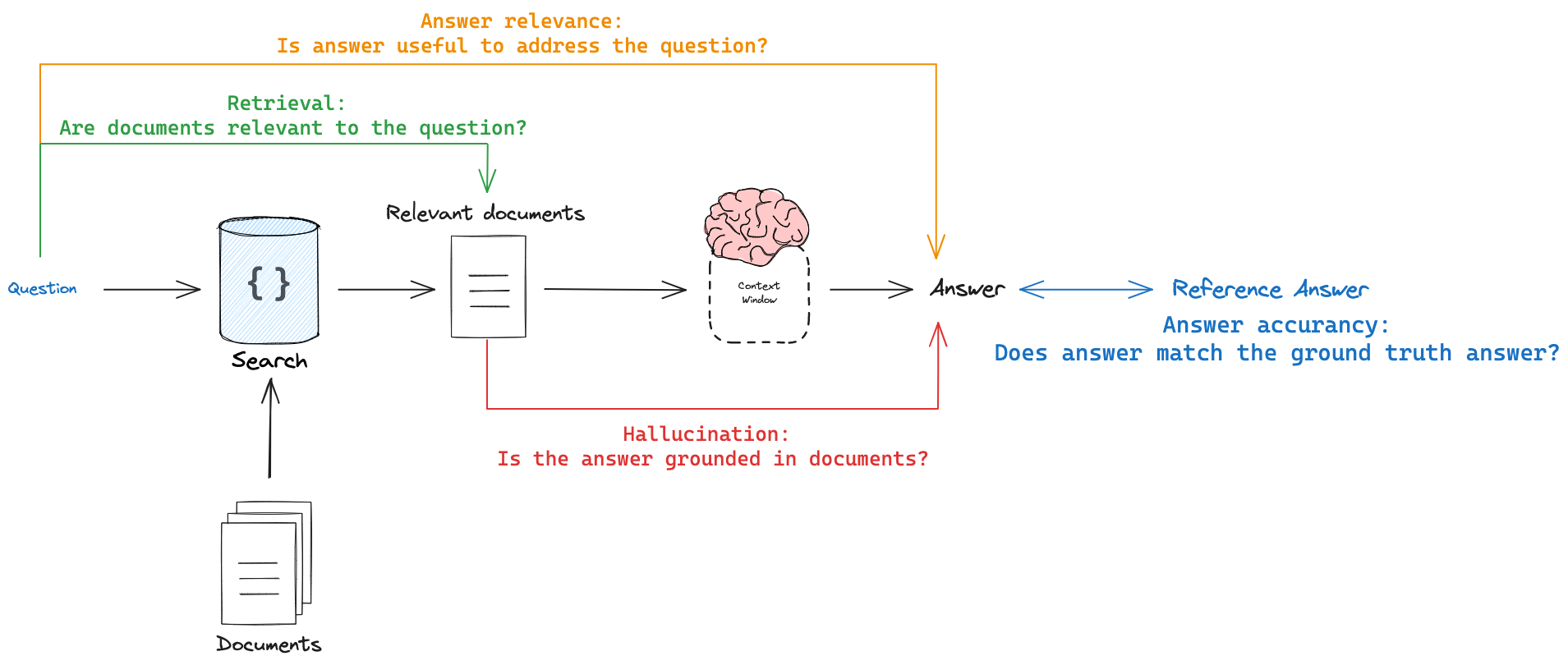
Each of these evals has something in common: it will compare text against some grounding (e.g., answer vs reference answer, etc).
We can use various built-in LangChainStringEvaluator types for this, but the same principles apply no matter which type of evaluator you are using. (see here).
All LangChainStringEvaluator implementations can accept 3 inputs:
prediction: The prediction string.
reference: The reference string.
input: The input string.
prediction is always required
input is required for most evaluators (criteria, score_string, labeled_criteria, labeled_score_string, qa, cot_qa)
reference is required for labeled evaluators, which are evaluators that grade against an expected value (qa, cot_qa, labeled_criteria, labeled_score_string)
Below, we will use this to perform eval.
RAG pipeline
To start, we build a RAG pipeline. We will be using LangChain strictly for creating the retriever and retrieving the relevant documents. The overall pipeline does not use LangChain. LangSmith works regardless of whether or not your pipeline is built with LangChain.
Note in the below example, we return the retrieved documents as part of the final answer. In a follow-up tutorial, we will showcase how to make use of these RAG evaluation techniques even when your pipline returns only the final answer!
%capture --no-stderr
! pip install langsmith langchain-community langchain chromadb tiktoken
We build an index using a set of LangChain docs.
### INDEX
from bs4 import BeautifulSoup as Soup
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
# Load
url = "https://python.langchain.com/docs/expression_language/"
loader = RecursiveUrlLoader(
url=url, max_depth=20, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embed
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# Index
retriever = vectorstore.as_retriever()
Next, we build a RAG chain that returns an answer and the retrieved documents as contexts.
### RAG
import openai
from langsmith import traceable
from langsmith.wrappers import wrap_openai
class RagBot:
def __init__(self, retriever, model: str = "gpt-4-0125-preview"):
self._retriever = retriever
# Wrapping the client instruments the LLM
self._client = wrap_openai(openai.Client())
self._model = model
@traceable()
def retrieve_docs(self, question):
return self._retriever.invoke(question)
@traceable()
def get_answer(self, question: str):
similar = self.retrieve_docs(question)
response = self._client.chat.completions.create(
model=self._model,
messages=[
{
"role": "system",
"content": "You are a helpful AI code assistant with expertise in LCEL."
" Use the following docs to produce a concise code solution to the user question.\n\n"
f"## Docs\n\n{similar}",
},
{"role": "user", "content": question},
],
)
# Evaluators will expect "answer" and "contexts"
return {
"answer": response.choices[0].message.content,
"contexts": [str(doc) for doc in similar],
}
rag_bot = RagBot(retriever)
response = rag_bot.get_answer("What is LCEL?")
response["answer"][:150]
'LangChain Expression Language (LCEL) is a declarative framework designed to streamline the process of composing and deploying complex chains of logica'
RAG Dataset
Next, we build a dataset of QA pairs based upon the documentation that we indexed.
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
_set_env("LANGCHAIN_API_KEY")
from langsmith import Client
# QA
inputs = [
"How can I directly pass a string to a runnable and use it to construct the input needed for my prompt?",
"How can I make the output of my LCEL chain a string?",
"How can I apply a custom function to one of the inputs of an LCEL chain?",
]
outputs = [
"Use RunnablePassthrough. from langchain_core.runnables import RunnableParallel, RunnablePassthrough; from langchain_core.prompts import ChatPromptTemplate; from langchain_openai import ChatOpenAI; prompt = ChatPromptTemplate.from_template('Tell a joke about: {input}'); model = ChatOpenAI(); runnable = ({'input' : RunnablePassthrough()} | prompt | model); runnable.invoke('flowers')",
"Use StrOutputParser. from langchain_openai import ChatOpenAI; from langchain_core.prompts import ChatPromptTemplate; from langchain_core.output_parsers import StrOutputParser; prompt = ChatPromptTemplate.from_template('Tell me a short joke about {topic}'); model = ChatOpenAI(model='gpt-3.5-turbo') #gpt-4 or other LLMs can be used here; output_parser = StrOutputParser(); chain = prompt | model | output_parser",
"Use RunnableLambda with itemgetter to extract the relevant key. from operator import itemgetter; from langchain_core.prompts import ChatPromptTemplate; from langchain_core.runnables import RunnableLambda; from langchain_openai import ChatOpenAI; def length_function(text): return len(text); chain = ({'prompt_input': itemgetter('foo') | RunnableLambda(length_function),} | prompt | model); chain.invoke({'foo':'hello world'})",
]
qa_pairs = [{"question": q, "answer": a} for q, a in zip(inputs, outputs)]
# Create dataset
client = Client()
dataset_name = "RAG_test_LCEL"
dataset = client.create_dataset(
dataset_name=dataset_name,
description="QA pairs about LCEL.",
)
client.create_examples(
inputs=[{"question": q} for q in inputs],
outputs=[{"answer": a} for a in outputs],
dataset_id=dataset.id,
)
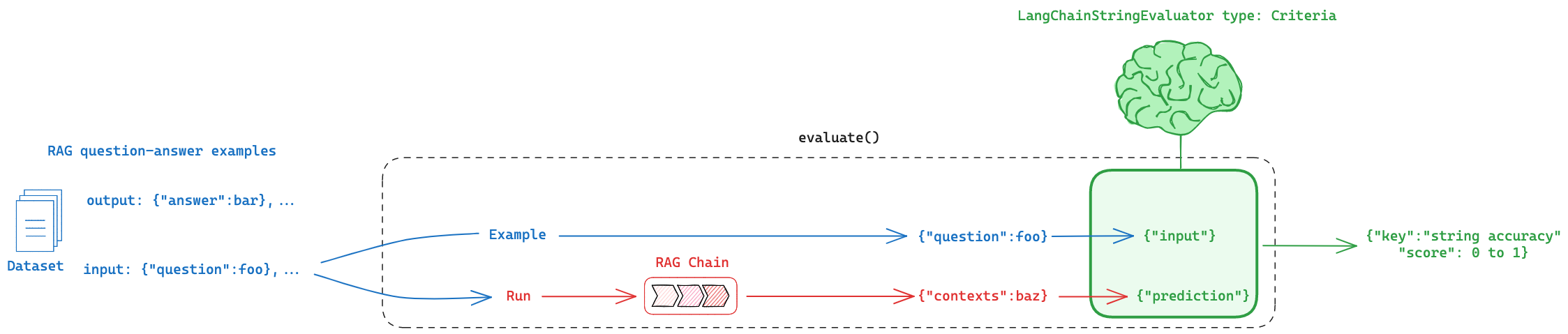
RAG Evaluators
Type 1: Reference Answer
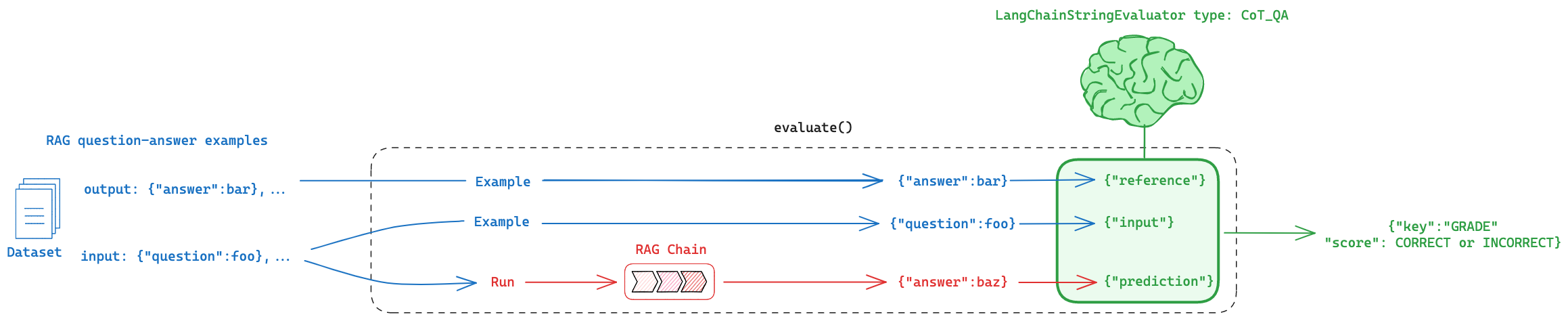
First, lets consider the case in which we want to compare our RAG chain answer to a reference answer.
This is shown on the far right (blue):
Here is the eval process we will use:
Eval flow
We will use a LangChainStringEvaluator to compare RAG chain answers to reference (ground truth) answers.
There are many types of LangChainStringEvaluator see options.
For comparing questions and answers, I like to use LLM-as-judge evaluators:
QACoTQA
For example, CoT_QA uses the eval prompt defined here.
And all LangChainStringEvaluator expose a common interface to pass the chain and dataset inputs:
questionfrom the dataset ->inputanswerfrom the dataset ->referenceanswerfrom the LLM ->prediction
# RAG chain
def predict_rag_answer(example: dict):
"""Use this for answer evaluation"""
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"]}
def predict_rag_answer_with_context(example: dict):
"""Use this for evaluation of retrieved documents and hallucinations"""
response = rag_bot.get_answer(example["question"])
return {"answer": response["answer"], "contexts": response["contexts"]}
from langsmith.evaluation import LangChainStringEvaluator, evaluate
# Evaluator
qa_evalulator = [
LangChainStringEvaluator(
"cot_qa",
prepare_data=lambda run, example: {
"prediction": run.outputs["answer"],
"reference": example.outputs["answer"],
"input": example.inputs["question"],
},
)
]
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer,
data=dataset_name,
evaluators=qa_evalulator,
experiment_prefix="rag-qa-oai",
metadata={"variant": "LCEL context, gpt-3.5-turbo"},
)
View the evaluation results for experiment: 'rag-qa-oai-d02f7ab6' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/f604a1c9-1542-4a5f-a413-75fb9b413533/compare?selectedSessions=eaf4a0a8-2bca-4cf9-8088-4222c02b8e80
0it [00:00, ?it/s]
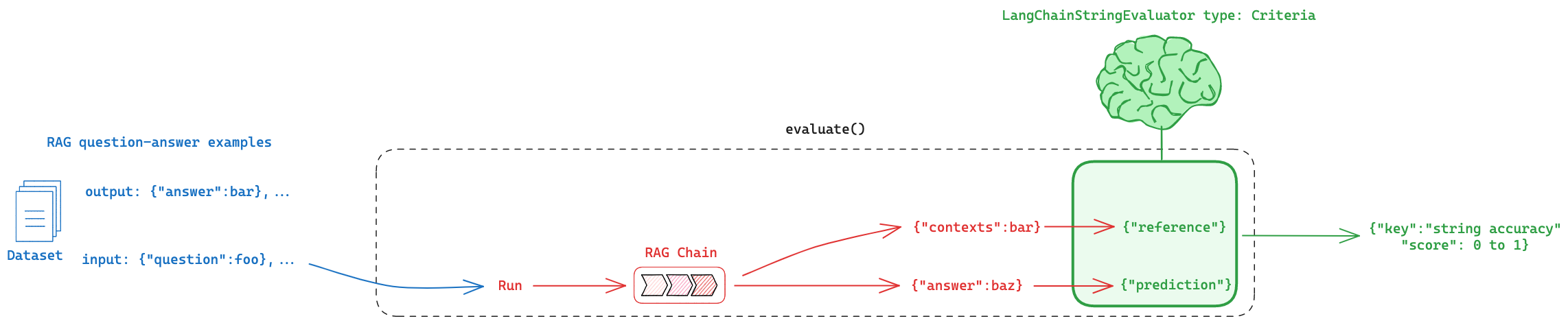
Type 2: Answer Hallucination
Second, lets consider the case in which we want to compare our RAG chain answer to the retrieved documents.
This is shown in the red in the top figure.
Eval flow
We will use a LangChainStringEvaluator, as mentioned above.
There are many types of LangChainStringEvaluator.
For comparing documents and answers, a common built-in LangChainStringEvaluator options is Criteria here because we want to supply custom criteria.
We will use labeled_score_string as an LLM-as-judge evaluator, which uses the eval prompt defined here.
Here, we only need to use two inputs of the LangChainStringEvaluator interface:
contextsfrom LLM chain ->referenceanswerfrom the LLM chain ->prediction
from langsmith.evaluation import LangChainStringEvaluator, evaluate
answer_hallucination_evaluator = LangChainStringEvaluator(
"labeled_score_string",
config={
"criteria": {
"accuracy": """Is the Assistant's Answer grounded in the Ground Truth documentation? A score of [[1]] means that the
Assistant answer contains is not at all based upon / grounded in the Groun Truth documentation. A score of [[5]] means
that the Assistant answer contains some information (e.g., a hallucination) that is not captured in the Ground Truth
documentation. A score of [[10]] means that the Assistant answer is fully based upon the in the Ground Truth documentation."""
},
# If you want the score to be saved on a scale from 0 to 1
"normalize_by": 10,
},
prepare_data=lambda run, example: {
"prediction": run.outputs["answer"],
"reference": run.outputs["contexts"],
"input": example.inputs["question"],
},
)
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer_with_context,
data=dataset_name,
evaluators=[answer_hallucination_evaluator],
experiment_prefix="rag-qa-oai-hallucination",
# Any experiment metadata can be specified here
metadata={
"variant": "LCEL context, gpt-3.5-turbo",
},
)
View the evaluation results for experiment: 'rag-qa-oai-hallucination-ec7ec336' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/f604a1c9-1542-4a5f-a413-75fb9b413533/compare?selectedSessions=909d9755-4ccb-48ff-b589-cd3d61008b29
0it [00:00, ?it/s]
Type 3: Document Relevance to Question
Finally, lets consider the case in which we want to compare our RAG chain document retrieval to the question.
This is shown in green in the top figure.
Eval flow
We will use a LangChainStringEvaluator, as mentioned above.
For comparing documents and answers, common built-in LangChainStringEvaluator options are Criteria here because we want to supply custom criteria.
We will use score_string as an LLM-as-judge evaluator (docs), which uses the eval prompt defined here.
Here, we only need to use two inputs of the LangChainStringEvaluator interface:
questionfrom LLM chain ->referencecontextsfrom the LLM chain ->prediction
from langsmith.evaluation import LangChainStringEvaluator, evaluate
import textwrap
docs_relevance_evaluator = LangChainStringEvaluator(
"score_string",
config={
"criteria": {
"document_relevance": textwrap.dedent(
"""The response is a set of documents retrieved from a vectorstore. The input is a question
used for retrieval. You will score whether the Assistant's response (retrieved docs) is relevant to the Ground Truth
question. A score of [[1]] means that none of the Assistant's response documents contain information useful in answering or addressing the user's input.
A score of [[5]] means that the Assistant answer contains some relevant documents that can at least partially answer the user's question or input.
A score of [[10]] means that the user input can be fully answered using the content in the first retrieved doc(s)."""
)
},
# If you want the score to be saved on a scale from 0 to 1
"normalize_by": 10,
},
prepare_data=lambda run, example: {
"prediction": run.outputs["contexts"],
"input": example.inputs["question"],
},
)
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer_with_context,
data=dataset_name,
evaluators=[docs_relevance_evaluator],
experiment_prefix="rag-qa-oai-doc-relevance",
# Any experiment metadata can be specified here
metadata={
"variant": "LCEL context, gpt-3.5-turbo",
},
)
View the evaluation results for experiment: 'rag-qa-oai-doc-relevance-9cce8945' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/f604a1c9-1542-4a5f-a413-75fb9b413533/compare?selectedSessions=d05253ce-6fea-46b7-84db-300b49f081b8
0it [00:00, ?it/s]
Evaluating intermediate traces
What if we didn't explicity return documents from our RAG chain?
In this case, we can isolate them as intermediate chain values.
from langchain_openai import ChatOpenAI
from langsmith.schemas import Example, Run
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
def document_relevance_grader(root_run: Run, example: Example) -> dict:
"""
A simple evaluator that checks to see if retrieved documents are relevant to the question
"""
# Get documents and question
rag_pipeline_run = next(run for run in root_run.child_runs if run.name == "get_answer")
retrieve_run = next(run for run in rag_pipeline_run.child_runs if run.name == "retrieve_docs")
doc_txt = "\n\n".join(doc.page_content for doc in retrieve_run.outputs["output"])
question = retrieve_run.inputs["question"]
# Data model for grade
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: int = Field(description="Documents are relevant to the question, 1 or 0")
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 1 or 0 score, where 1 means that the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
score = retrieval_grader.invoke({"question": question, "document": doc_txt})
return {"key": "document_relevance", "score": int(score.binary_score)}
def answer_hallucination_grader(root_run: Run, example: Example) -> dict:
"""
A simple evaluator that checks to see the answer is grounded in the documents
"""
# Get documents and answer
rag_pipeline_run = next(run for run in root_run.child_runs if run.name == "get_answer")
retrieve_run = next(run for run in rag_pipeline_run.child_runs if run.name == "retrieve_docs")
doc_txt = "\n\n".join(doc.page_content for doc in retrieve_run.outputs["output"])
generation = rag_pipeline_run.outputs["answer"]
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: int = Field(description="Answer is grounded in the facts, 1 or 0")
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 1 or 0, where 1 means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
score = hallucination_grader.invoke({"documents": doc_txt, "generation": generation})
return {"key": "answer_hallucination", "score": int(score.binary_score)}
from langsmith.evaluation import evaluate
dataset_name = "RAG_test_LCEL"
experiment_results = evaluate(
predict_rag_answer,
data=dataset_name,
evaluators=[document_relevance_grader,answer_hallucination_grader],
experiment_prefix= "LCEL context, gpt-3.5-turbo"
)
View the evaluation results for experiment: 'LCEL context, gpt-3.5-turbo-19736d4b' at: https://smith.langchain.com/o/1fa8b1f4-fcb9-4072-9aa9-983e35ad61b8/datasets/e5197c9e-24ab-405a-82c5-cef7afadb1b4/compare?selectedSessions=7bf48d82-c2df-4b80-a020-cfa26fac0764
0it [00:00, ?it/s]