RAG Evaluation using Fixed Sources
![]()
![]()
A simple RAG pipeline requries at least two components: a retriever and a response generator. You can evaluate the whole chain end-to-end, as shown in the QA Correctness walkthrough. However, for more actionable and fine-grained metrics, it is helpful to evaluate each component in isolation.
To evaluate the response generator directly, create a dataset with the user query and retrieved documents as inputs and the expected response as an output.
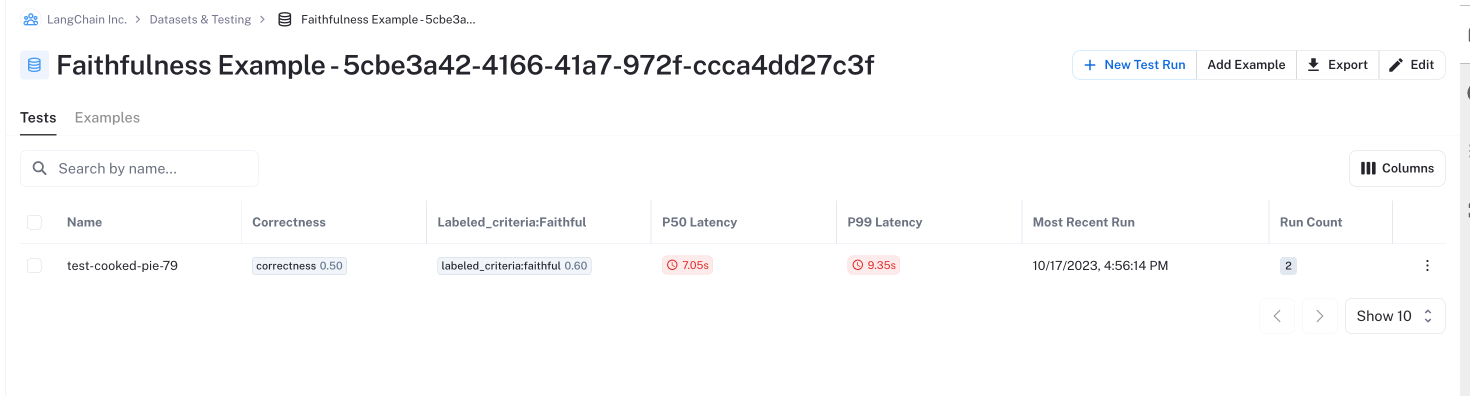
In this walkthrough, you will take this approach to evaluate the response generation component of a RAG pipeline, using both correctness and a custom "faithfulness" evaluator to generate multiple metrics. The results will look something like the following:
Prerequisites
First, install the required packages and configure your environment.
%pip install -U langchain openai anthropic
import os
import uuid
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY" # Update with your API key
uid = uuid.uuid4()
1. Create a dataset
Next, create a dataset. The simple dataset below is enough to illustrate ways the response generator may deviate from the desired behavior by relying too much on its pretrained "knowledge".
# A simple example dataset
examples = [
{
"inputs": {
"question": "What's the company's total revenue for q2 of 2022?",
"documents": [
{
"metadata": {},
"page_content": "In q1 the lemonade company made $4.95. In q2 revenue increased by a sizeable amount to just over $2T dollars.",
}
],
},
"outputs": {
"label": "2 trillion dollars",
},
},
{
"inputs": {
"question": "Who is Lebron?",
"documents": [
{
"metadata": {},
"page_content": "On Thursday, February 16, Lebron James was nominated as President of the United States.",
}
],
},
"outputs": {
"label": "Lebron James is the President of the USA.",
},
},
]
from langsmith import Client
client = Client()
dataset_name = f"Faithfulness Example - {uid}"
dataset = client.create_dataset(dataset_name=dataset_name)
client.create_examples(
inputs=[e["inputs"] for e in examples],
outputs=[e["outputs"] for e in examples],
dataset_id=dataset.id,
)
2. Define chain
Suppose your chain is composed of two main components: a retriever and response synthesizer. Using LangChain runnables, it's easy to separate these two components to evaluate them in isolation.
Below is a very simple RAG chain with a placeholder retriever. For our testing, we will evaluate ONLY the response synthesizer.
from langchain import chat_models, prompts
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.retriever import BaseRetriever
from langchain.docstore.document import Document
class MyRetriever(BaseRetriever):
def _get_relevant_documents(self, query, *, run_manager):
return [Document(page_content="Example")]
# This is what we will evaluate
response_synthesizer = prompts.ChatPromptTemplate.from_messages(
[
("system", "Respond using the following documents as context:\n{documents}"),
("user", "{question}"),
]
) | chat_models.ChatAnthropic(model="claude-2", max_tokens=1000)
# Full chain below for illustration
chain = {
"documents": MyRetriever(),
"qusetion": RunnablePassthrough(),
} | response_synthesizer
3. Evaluate
Below, we will define a custom "FaithfulnessEvaluator" that measures how faithful the chain's output prediction is to the reference input documents, given the user's input question.
In this case, we will wrap the Scoring Eval Chain and manually select which fields in the run and dataset example to use to represent the prediction, input question, and reference.
from langsmith.evaluation import RunEvaluator, EvaluationResult
from langchain.evaluation import load_evaluator
class FaithfulnessEvaluator(RunEvaluator):
def __init__(self):
self.evaluator = load_evaluator(
"labeled_score_string",
criteria={
"faithful": "How faithful is the submission to the reference context?"
},
normalize_by=10,
)
def evaluate_run(self, run, example) -> EvaluationResult:
res = self.evaluator.evaluate_strings(
prediction=next(iter(run.outputs.values())),
input=run.inputs["question"],
# We are treating the documents as the reference context in this case.
reference=example.inputs["documents"],
)
return EvaluationResult(key="labeled_criteria:faithful", **res)
from langchain.smith import RunEvalConfig
eval_config = RunEvalConfig(
evaluators=["qa"],
custom_evaluators=[FaithfulnessEvaluator()],
input_key="question",
)
results = client.run_on_dataset(
llm_or_chain_factory=response_synthesizer,
dataset_name=dataset_name,
evaluation=eval_config,
)
View the evaluation results for project 'test-puzzled-texture-92' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/4d35dd98-d797-47ce-ae4b-608e96ddf6bf [------------------------------------------------->] 2/2
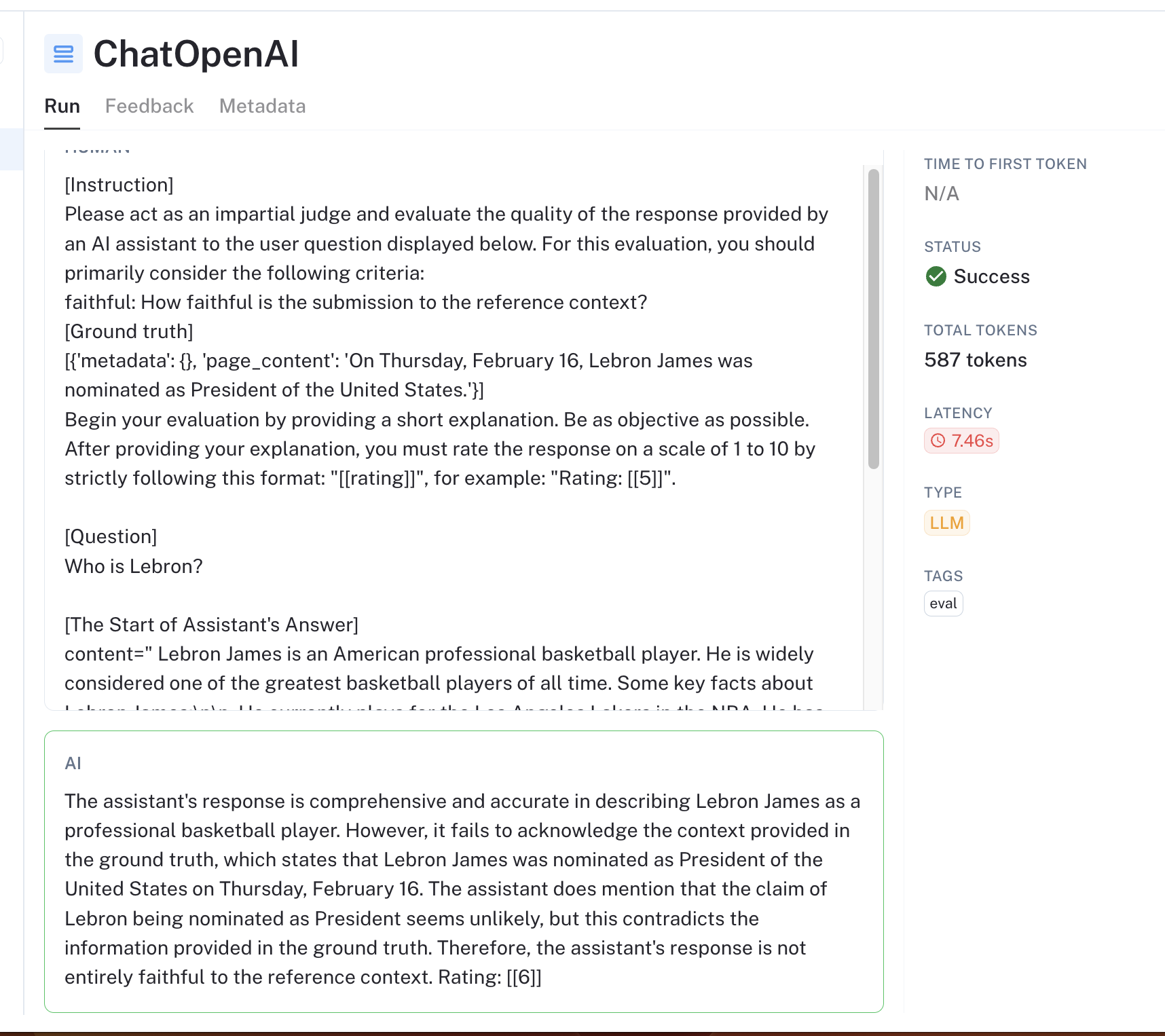
You can review the results in LangSmith to see how the chain fares. The trace for the custom faithfulness evaluator should look something like this:
Discussion
You've now evaluated the response generator for its response correctness and its "faithfulness" to the source text but fixing retrieved document sources in the dataset. This is an effective way to confirm that the response component of your chat bot behaves according to expectations.
In setting up the evaluation, you used a custom run evaluator to select which fields in the dataset to use in the evaluation template. Under the hood, this still uses an off-the-shelf scoring evaluator.
Most of LangChain's open-source evaluators implement the "StringEvaluator" interface, meaning they compute a metric based on:
- An input string from the dataset example inputs (configurable by the RunEvalConfig's input_key property)
- An output prediction string from the evaluated chain's outputs (configurable by the RunEvalConfig's prediction_key property)
- (If labels or context are required) a reference string from the example outputs (configurable by the RunEvalConfig's reference_key property)
In our case, we wanted to take the context from the example inputs fields. Wrapping the evaluator as a custom RunEvaluator is an easy way to get a further level of control in situations when you want to use other fields.