Evaluation Quick Start
This guide helps you get started evaluating your AI system using LangSmith, so you can deploy the best perfoming model for your needs. This guide gets you started with the basics.
1. Install LangSmith
- Python
- TypeScript
pip install -U langsmith
yarn add langchain
2. Evaluate
Evalution requires a system to test, data to serve as test cases, and optionally evaluators to grade the results.
- Python
- TypeScript
from langsmith import Client
from langsmith.schemas import Run, Example
from langsmith.evaluation import evaluate
import openai
from langsmith.wrappers import wrap_openai
client = Client()
# Define dataset: these are your test cases
dataset_name = "Rap Battle Dataset"
dataset = client.create_dataset(dataset_name, description="Rap battle prompts.")
client.create_examples(
inputs=[
{"question": "a rap battle between Atticus Finch and Cicero"},
{"question": "a rap battle between Barbie and Oppenheimer"},
],
outputs=[
{"must_mention": ["lawyer", "justice"]},
{"must_mention": ["plastic", "nuclear"]},
],
dataset_id=dataset.id,
)
# Define AI system
openai_client = wrap_openai(openai.Client())
def predict(inputs: dict) -> dict:
messages = [{"role": "user", "content": inputs["question"]}]
response = openai_client.chat.completions.create(messages=messages, model="gpt-3.5-turbo")
return {"output": response}
# Define evaluators
def must_mention(run: Run, example: Example) -> dict:
prediction = run.outputs.get("output") or ""
required = example.outputs.get("must_mention") or []
score = all(phrase in prediction for phrase in required)
return {"key":"must_mention", "score": score}
experiment_results = evaluate(
predict, # Your AI system
data=dataset_name, # The data to predict and grade over
evaluators=[must_mention], # The evaluators to score the results
experiment_prefix="rap-generator", # A prefix for your experiment names to easily identify them
metadata={
"version": "1.0.0",
},
)
import { Client } from "langsmith";
import { Run, Example } from "langsmith";
import { EvaluationResult } from "langsmith/evaluation";
// Note: native evaluate() function support coming soon to the LangSmith TS SDK
import { runOnDataset } from "langchain/smith";
import OpenAI from "openai";
const client = new Client();
// Define dataset: these are your test cases
const datasetName = "Rap Battle Dataset";
const dataset = await client.createDataset(datasetName, {
description: "Rap battle prompts.",
});
await client.createExamples({
inputs: [
{question: "a rap battle between Atticus Finch and Cicero"},
{question: "a rap battle between Barbie and Oppenheimer"},
],
outputs: [
{must_mention: ["lawyer", "justice"]},
{must_mention: ["plastic", "nuclear"]},
],
datasetId: dataset.id,
});
// Define AI system
const openaiClient = new OpenAI();
async function predictResult({ question }: { question: string }) {
const messages = [{ "role": "user", "content": question }];
const output = await openaiClient.chat.completions.create({
model: "gpt-3.5-turbo",
messages: messages
});
return { output };
}
// Define evaluators
const mustMention = async ({ run, example }: { run: Run; example?: Example; }): Promise<EvaluationResult> => {
const mustMention: string[] = example?.outputs?.must_contain ?? [];
const score = mustMention.every((phrase) =>
run?.outputs?.output.includes(phrase)
);
return {
key: "must_mention",
score: score,
};
};
await runOnDataset(
predictResult, // Your AI system
datasetName, // The data to predict and grade over
{
evaluationConfig: {customEvaluators: [mustMention]
},
projectMetadata: {
version: "1.0.0",
},
});
Configure your API key, then run the script to evaluate your system.
- Python
- TypeScript
export LANGCHAIN_API_KEY=<your api key>
export LANGCHAIN_API_KEY=<your api key>
3. Review Results
The evaluation results will be streamed to a new experiment linked to your "Rap Battle Dataset". You can view the results by clicking on the link printed by the evaluate function or by navigating to the Datasets & Testing page, clicking "Rap Battle Dataset", and viewing the latest test run.
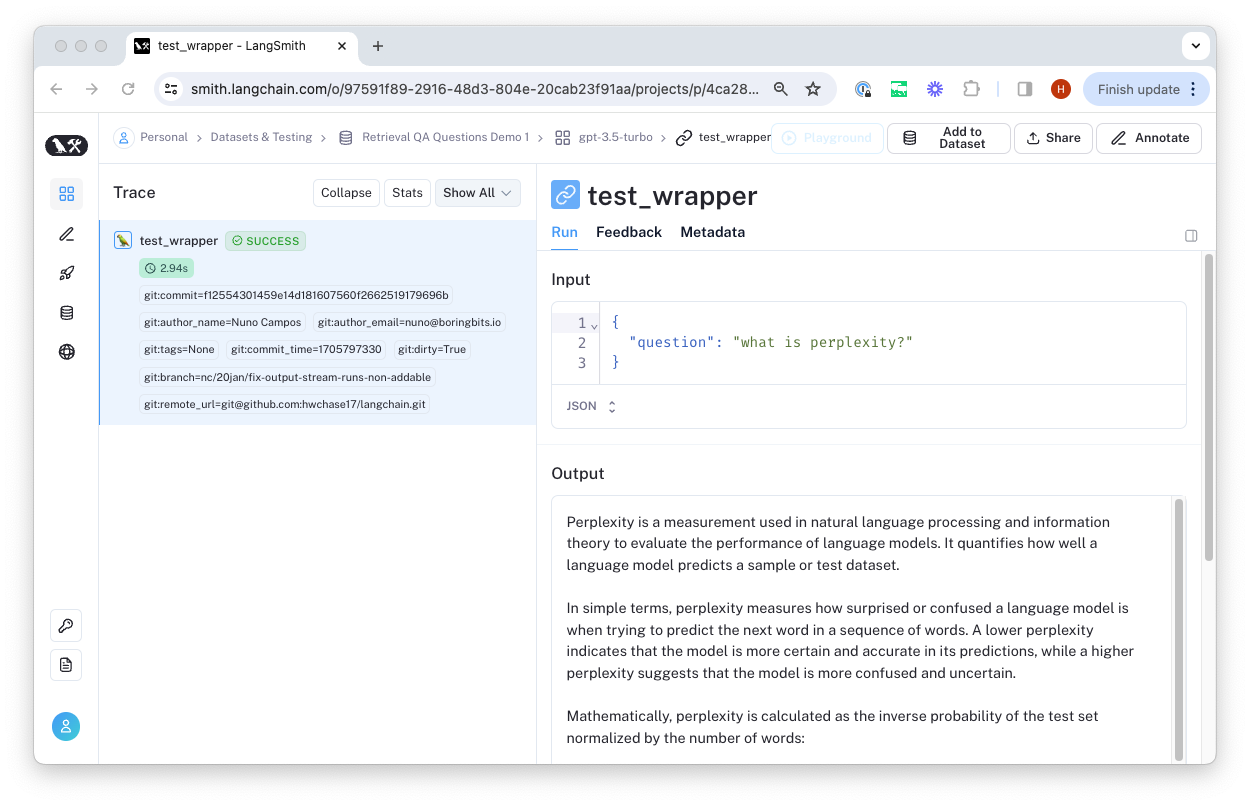
There, you can inspect the traces and feedback generated from the evaluation configuration.
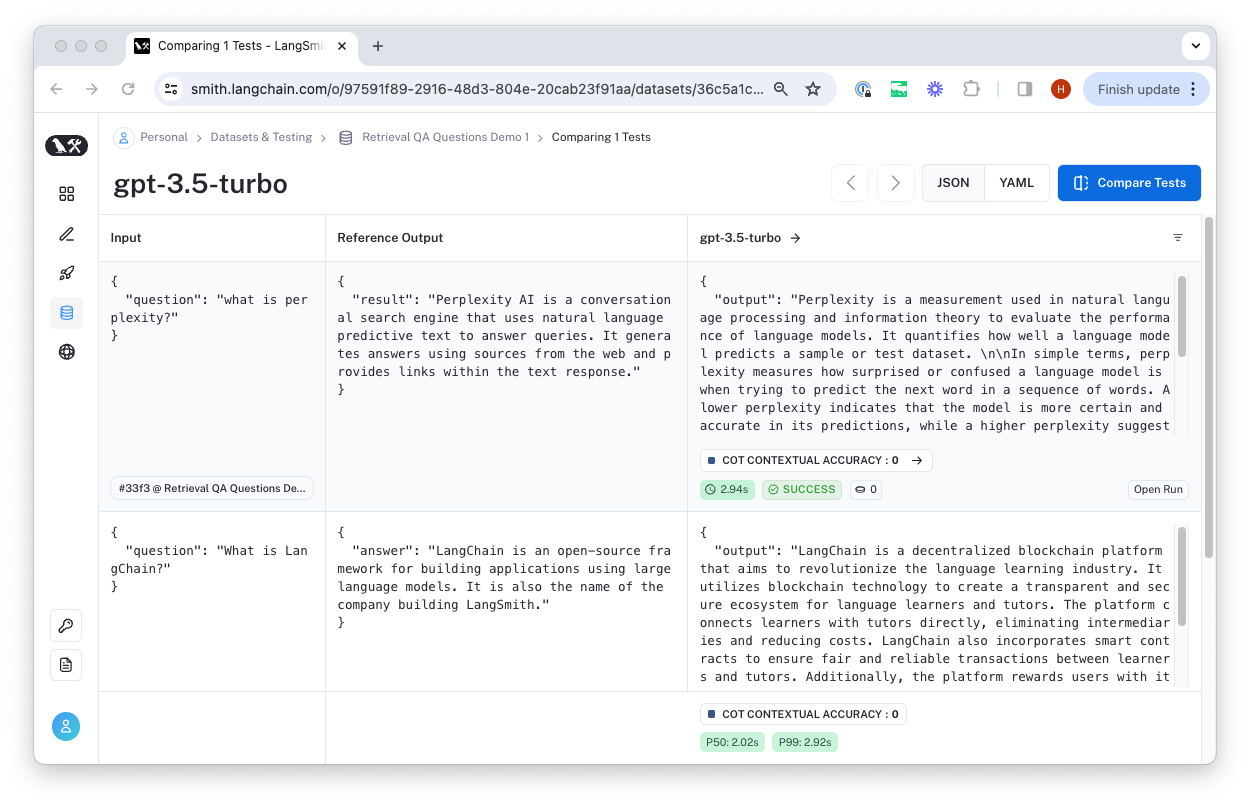
You can click "Open Run" to view the trace and feedback generated for that example.
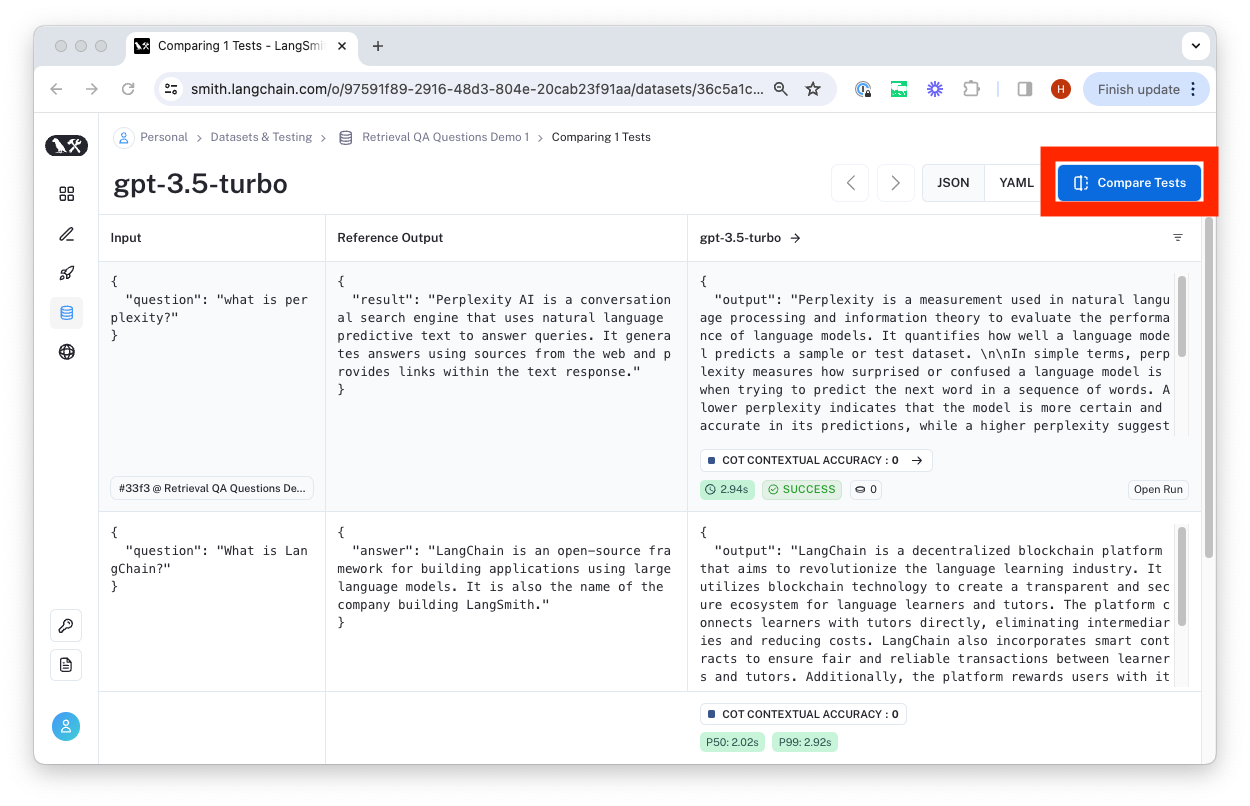
To compare to another test on this dataset, you can click "Compare Tests".
More on evaluation
Congratulations! You've now created a dataset and used it to evaluate your agent or LLM. To learn how to make your own custom evaluators, review the Custom Evaluator guide. To learn more about some pre-built evaluators available in the LangChain open-source library, check out the LangChain Evaluators guide.