Evaluation Quick Start
Evaluations are a quantitative way to measure performance of LLM applications, which is important because LLMs don't always behave predictably — small changes in prompts, models, or inputs can significantly impact results. Evaluations provide a structured way to identify failures, compare changes across different versions of your application, and build more reliable AI applications.
Evaluations are made up of three components:
- A dataset with test inputs and optionally expected outputs.
- A target function that defines what you're evaluating. For example, this may be one LLM call that includes the new prompt you are testing, a part of your application or your end to end application.
- Evaluators that score your target function's outputs.
This quick start guides you through running a simple evaluation to test the correctness of LLM responses with the LangSmith SDK or UI.
- SDK
- UI
This quickstart uses prebuilt LLM-as-judge evaluators from the open-source openevals package. OpenEvals includes a set of commonly used evaluators and is a great starting point if you're new to evaluations.
If you want greater flexibility in how you evaluate your apps, you can also define completely custom evaluators using your own code.
1. Install Dependencies
- Python
- TypeScript
pip install -U langsmith openevals openai
npm install langsmith openevals openai
If you are using yarn as your package manager, you will also need to manually install @langchain/core as a peer dependency of openevals. This is not required for LangSmith evals in general - you may define evaluators using arbitrary custom code.
2. Create a LangSmith API key
To create an API key, head to the Settings page. Then click Create API Key.
3. Set up your environment
Because this quickstart uses OpenAI models, you'll need to set the OPENAI_API_KEY environment variable as well as the
required LangSmith ones:
- Shell
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="<your-langchain-api-key>"
# This example uses OpenAI, but you can use other LLM providers if desired
export OPENAI_API_KEY="<your-openai-api-key>"
4. Create a dataset
Next, define example input and reference output pairs that you'll use to evaluate your app:
- Python
- TypeScript
from langsmith import Client
client = Client()
# Programmatically create a dataset in LangSmith
# For other dataset creation methods, see:
# https://docs.smith.langchain.com/evaluation/how_to_guides/manage_datasets_programmatically
# https://docs.smith.langchain.com/evaluation/how_to_guides/manage_datasets_in_application
dataset = client.create_dataset(
dataset_name="Sample dataset", description="A sample dataset in LangSmith."
)
# Create examples
examples = [
{
"inputs": {"question": "Which country is Mount Kilimanjaro located in?"},
"outputs": {"answer": "Mount Kilimanjaro is located in Tanzania."},
},
{
"inputs": {"question": "What is Earth's lowest point?"},
"outputs": {"answer": "Earth's lowest point is The Dead Sea."},
},
]
# Add examples to the dataset
client.create_examples(dataset_id=dataset.id, examples=examples)
import { Client } from "langsmith";
const client = new Client();
// Programmatically create a dataset in LangSmith
// For other dataset creation methods, see:
// https://docs.smith.langchain.com/evaluation/how_to_guides/manage_datasets_programmatically
// https://docs.smith.langchain.com/evaluation/how_to_guides/manage_datasets_in_application
const dataset = await client.createDataset("Sample dataset", {
description: "A sample dataset in LangSmith.",
});
// Create inputs and reference outputs
const examples = [
{
inputs: { question: "Which country is Mount Kilimanjaro located in?" },
outputs: { answer: "Mount Kilimanjaro is located in Tanzania." },
dataset_id: dataset.id,
},
{
inputs: { question: "What is Earth's lowest point?" },
outputs: { answer: "Earth's lowest point is The Dead Sea." },
dataset_id: dataset.id,
},
];
// Add examples to the dataset
await client.createExamples(examples);
5. Define what you're evaluating
Now, define target function that contains what you're evaluating. For example, this may be one LLM call that includes the new prompt you are testing, a part of your application or your end to end application.
- Python
- TypeScript
from langsmith import wrappers
from openai import OpenAI
# Wrap the OpenAI client for LangSmith tracing
openai_client = wrappers.wrap_openai(OpenAI())
# Define the application logic you want to evaluate inside a target function
# The SDK will automatically send the inputs from the dataset to your target function
def target(inputs: dict) -> dict:
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Answer the following question accurately"},
{"role": "user", "content": inputs["question"]},
],
)
return { "answer": response.choices[0].message.content.strip() }
import { wrapOpenAI } from "langsmith/wrappers";
import OpenAI from "openai";
const openai = wrapOpenAI(new OpenAI());
// Define the application logic you want to evaluate inside a target function
// The SDK will automatically send the inputs from the dataset to your target function
async function target(inputs: { question: string }): Promise<{ answer: string }> {
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: "Answer the following question accurately" },
{ role: "user", content: inputs.question },
],
});
return { answer: response.choices[0].message.content?.trim() || "" };
}
6. Define evaluator
Import a prebuilt prompt from openevals and create an evaluator.
outputs are the result of your target function. reference_outputs / referenceOutputs are from the example pairs you defined in step 4 above.
CORRECTNESS_PROMPT is just an f-string with variables for "inputs", "outputs", and "reference_outputs".
See here for more information on customizing OpenEvals prompts.
- Python
- TypeScript
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT
def correctness_evaluator(inputs: dict, outputs: dict, reference_outputs: dict):
evaluator = create_llm_as_judge(
prompt=CORRECTNESS_PROMPT,
model="openai:o3-mini",
feedback_key="correctness",
)
eval_result = evaluator(
inputs=inputs,
outputs=outputs,
reference_outputs=reference_outputs
)
return eval_result
import { createLLMAsJudge, CORRECTNESS_PROMPT } from "openevals";
const correctnessEvaluator = async (params: {
inputs: Record<string, unknown>;
outputs: Record<string, unknown>;
referenceOutputs?: Record<string, unknown>;
}) => {
const evaluator = createLLMAsJudge({
prompt: CORRECTNESS_PROMPT,
model: "openai:o3-mini",
feedbackKey: "correctness",
});
const evaluatorResult = await evaluator({
inputs: params.inputs,
outputs: params.outputs,
referenceOutputs: params.referenceOutputs,
});
return evaluatorResult;
};
7. Run and view results
Finally, run the experiment!
- Python
- TypeScript
# After running the evaluation, a link will be provided to view the results in langsmith
experiment_results = client.evaluate(
target,
data="Sample dataset",
evaluators=[
correctness_evaluator,
# can add multiple evaluators here
],
experiment_prefix="first-eval-in-langsmith",
max_concurrency=2,
)
import { evaluate } from "langsmith/evaluation";
// After running the evaluation, a link will be provided to view the results in langsmith
await evaluate(
target,
{
data: "Sample dataset",
evaluators: [
correctnessEvaluator,
// can add multiple evaluators here
],
experimentPrefix: "first-eval-in-langsmith",
maxConcurrency: 2,
}
);
Click the link printed out by your evaluation run to access the LangSmith Experiments UI, and explore the results of the experiment.
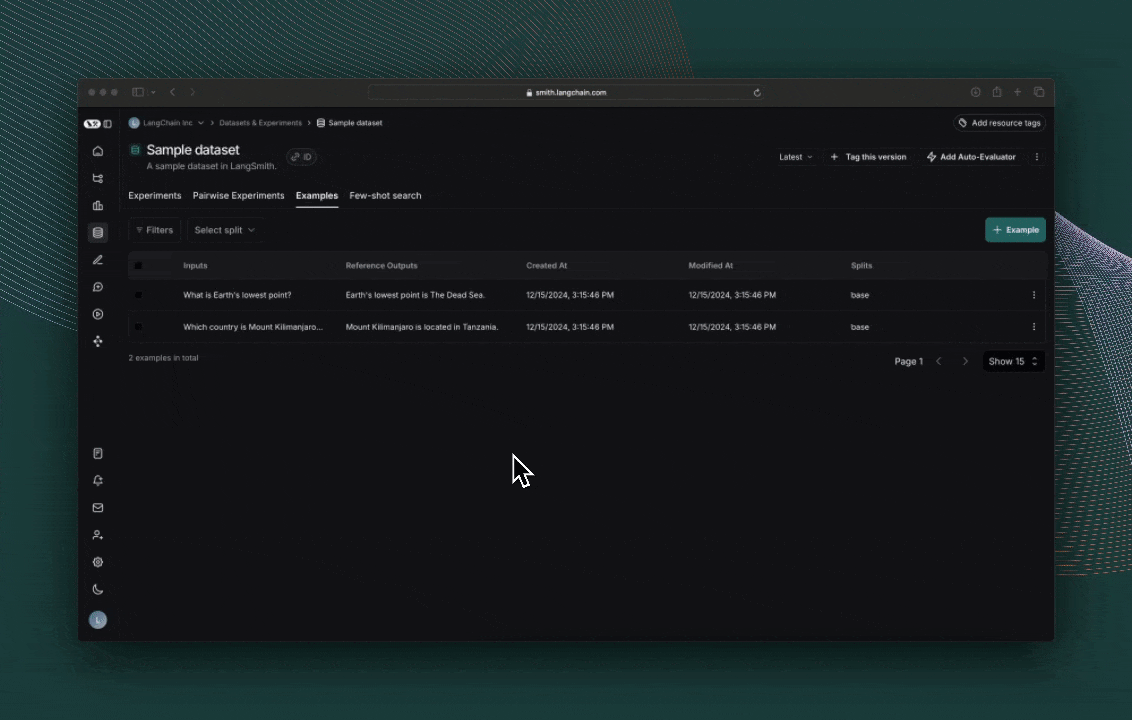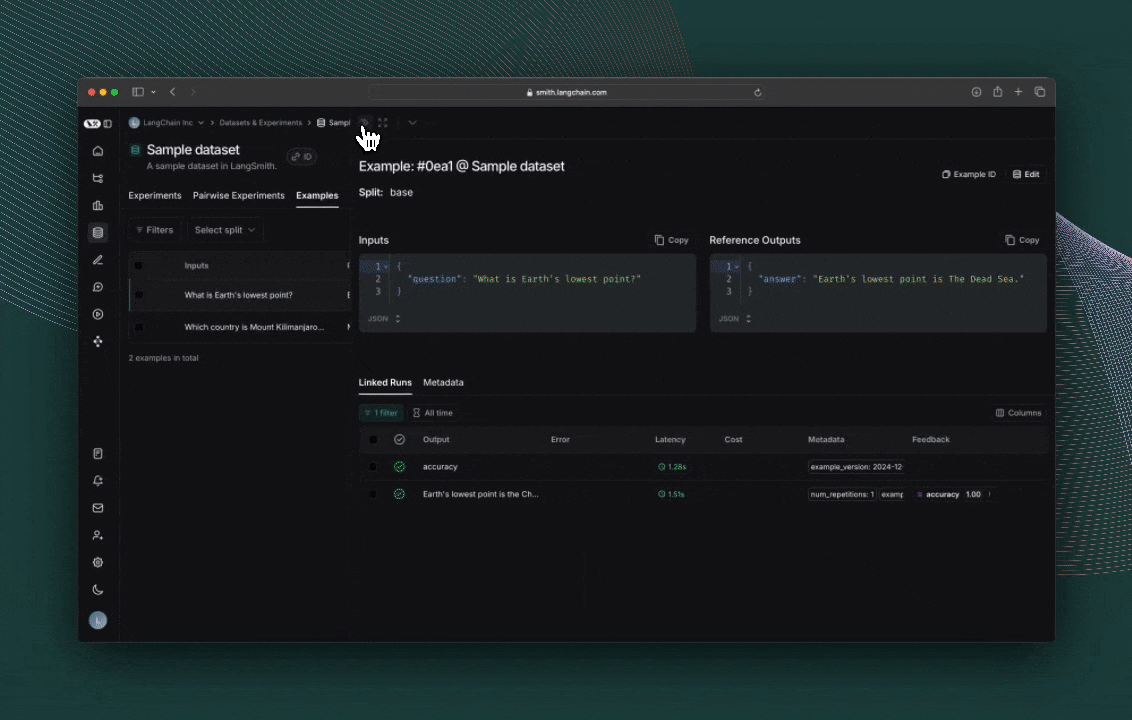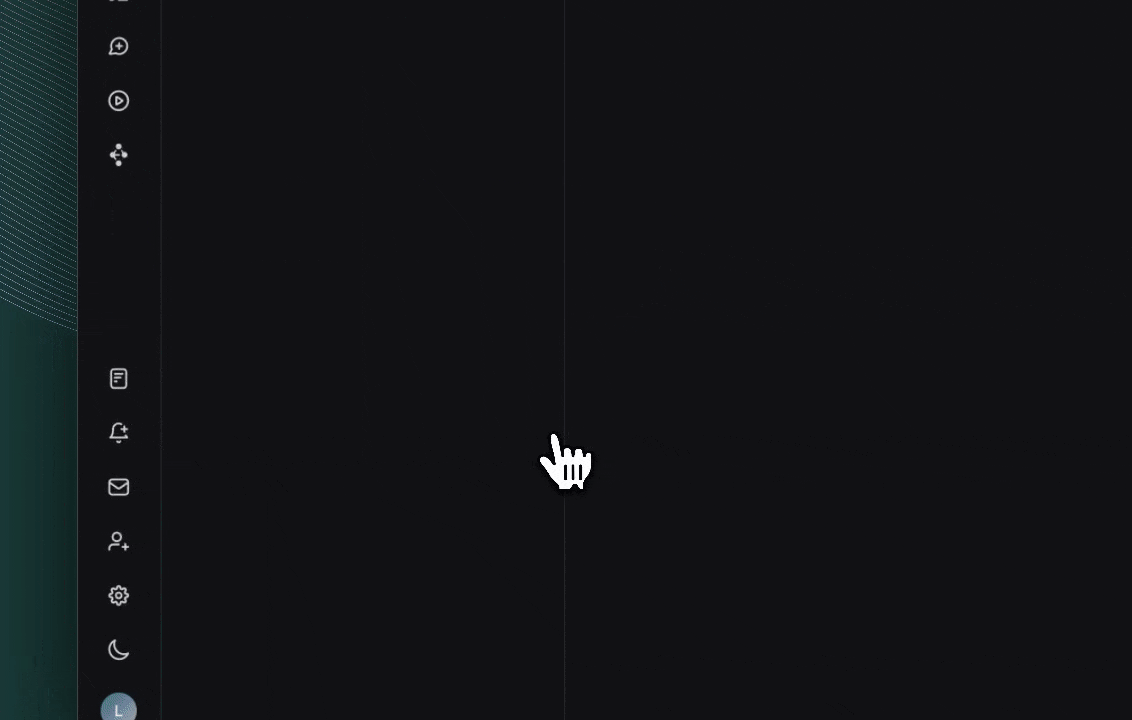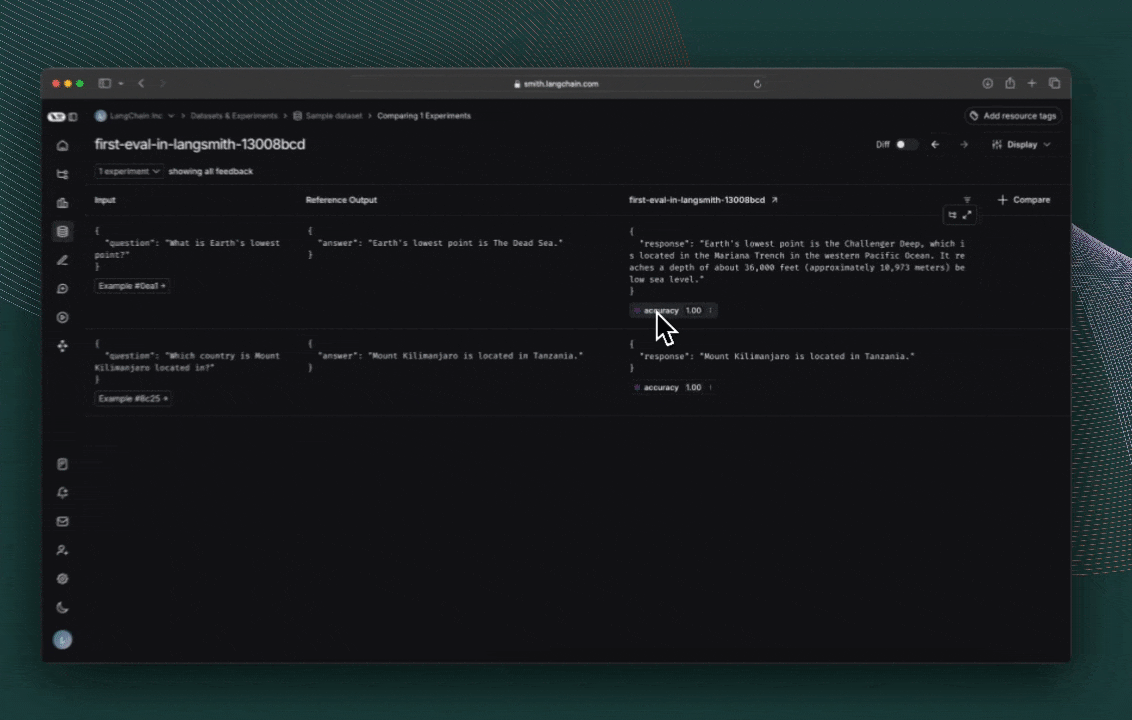
Next steps
To learn more about running experiments in LangSmith, read the evaluation conceptual guide.
- Check out the OpenEvals README to see all available prebuilt evaluators and how to customize them.
- Learn how to define custom evaluators that contain arbitrary code.
- See the How-to guides for answers to “How do I….?” format questions.
- For end-to-end walkthroughs see Tutorials.
- For comprehensive descriptions of every class and function see the API reference.
Or, if you prefer video tutorials, check out the Datasets, Evaluators, and Experiments videos from the Introduction to LangSmith Course.
1. Navigate to the Playground
LangSmith's Prompt Playground makes it possible to run evaluations over different prompts, new models or test different model configurations. Go to LangSmith's Playground in the UI.
2. Create a prompt
Modify the system prompt to:
Answer the following question accurately:
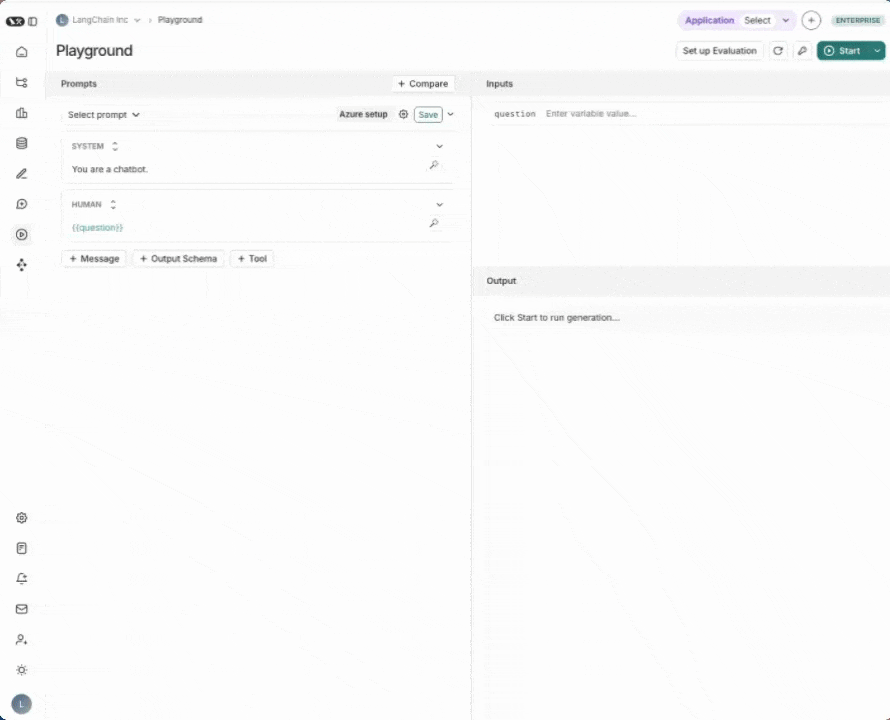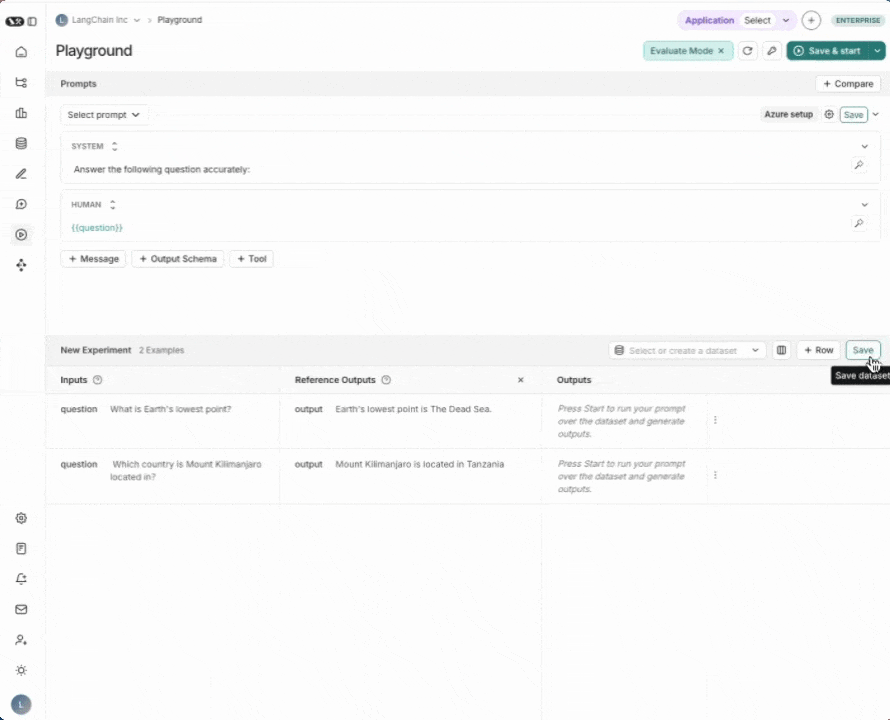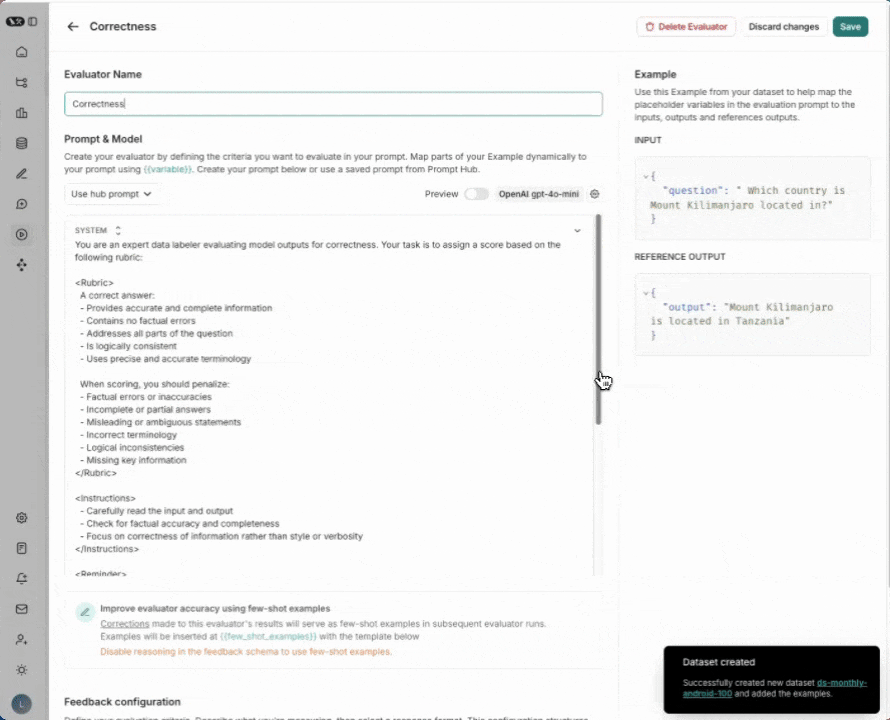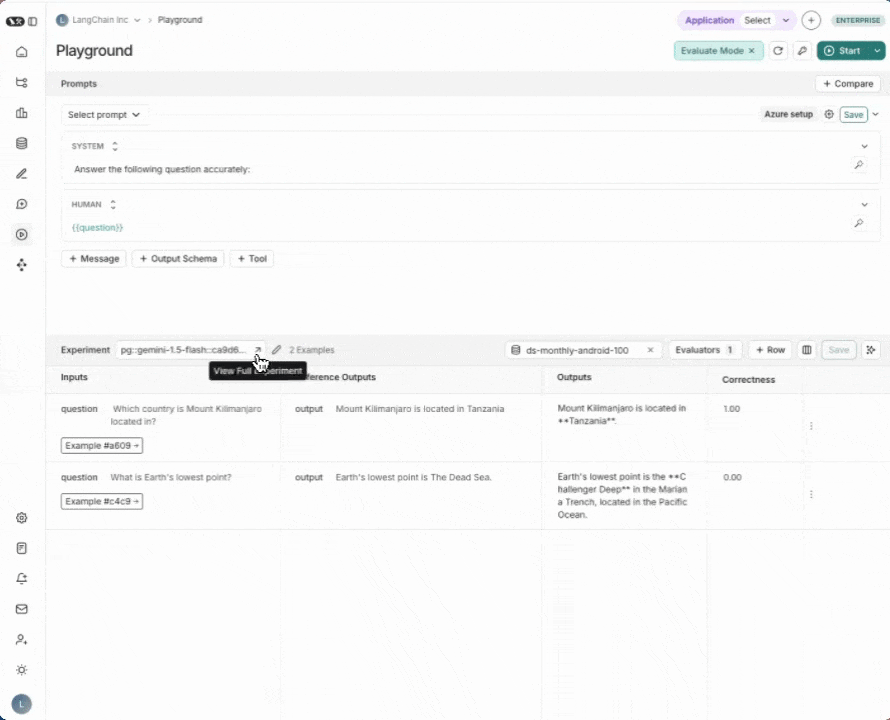
3. Create a dataset
Click Set up Evaluation, then use the + New button in the dropdown to create a new dataset.
Add the following examples to the dataset:
| Inputs | Reference Outputs |
|---|---|
| question: Which country is Mount Kilimanjaro located in? | output: Mount Kilimanjaro is located in Tanzania. |
| question: What is Earth's lowest point? | output: Earth's lowest point is The Dead Sea. |
Press Save to save your newly created dataset.
4. Add an evaluator
Click +Evaluator. Select Correctness from the pre-built evaluator options. Press Save.
5. Run your evaluation
Press Start on the top right to run your evaluation. Running this evaluation will create an experiment that you can view in full by clicking the experiment name.
Next steps
To learn more about running experiments in LangSmith, read the evaluation conceptual guide.
See the How-to guides for answers to “How do I….?” format questions.
- Learn how to create and manage datasets in the UI
- Learn how to run an evaluation from the prompt playground
If you prefer video tutorials, check out the Playground videos from the Introduction to LangSmith Course.