Evaluating Q&A Systems with Dynamic Data
![]()
![]()
In many real-world scenarios, the correct answer to a question may change over time. For instance, if you're building a Q&A system over a database or that connects to an API, the underlying data might be updated frequently. In such cases, you still want to measure the correctness of your system, but you'll want to do so in a way that accounts for these changes.
In the following tutorial, we'll use the age-old software practice of indirection to address this issue. Rather than storing labels directly as values, our labels will be references to look up the correct values. In this case, our labels will be queries that the custom evaluator can use to fetch the ground truth answer and compare it with the model's predictions.
This tutorial will walk you through the following steps:
- Create a dataset of questions and corresponding code snippets to fetch the answers.
- Define your Q&A system.
- Run evaluation using LangSmith with a custom evaluator.
- Re-test the system over time.
> Quick note: We are using a CSV file to simulate a real data source. This is not a real scenario and is meant to be illustrative.
Let's begin!
Prerequisites
This tutorial uses OpenAI for the model and LangChain to compose the chain. To make sure the tracing and evals are set up for LangSmith, please configure your API Key appropriately.
import os
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY" # Update with your API key
Install the required packages. We will use the latest version of langchain and use pandas as an example of a data store.
# %pip install -U "langchain[openai]" > /dev/null
# %pip install pandas > /dev/null
# %env OPENAI_API_KEY=<YOUR-API-KEY>```
1. Create a dataset
We will be using the Titanic dataset from here for our example. This dataset contains information about passengers on the Titanic, along with their outcomes.
First, define a set of questions and corresponding references showing how to retrieve the correct answer from the data. For the sake of the tutorial, we will use Python code snippets, but the tactic can be generally applied to any other form of indirection, such as storing API requests or search arguments.
The references will be used by our evaluator to fetch the correct answer.
questions = [
("How many passengers were on the Titanic?", "len(df)"),
("How many passengers survived?", "df['Survived'].sum()"),
("What was the average age of the passengers?", "df['Age'].mean()"),
("How many male and female passengers were there?", "df['Sex'].value_counts()"),
("What was the average fare paid for the tickets?", "df['Fare'].mean()"),
("How many passengers were in each class?", "df['Pclass'].value_counts()"),
(
"What was the survival rate for each gender?",
"df.groupby('Sex')['Survived'].mean()",
),
(
"What was the survival rate for each class?",
"df.groupby('Pclass')['Survived'].mean()",
),
(
"Which port had the most passengers embark from?",
"df['Embarked'].value_counts().idxmax()",
),
(
"How many children under the age of 18 survived?",
"df[df['Age'] < 18]['Survived'].sum()",
),
]
Next, create the dataset! You can use the LangSmith SDK to do so. Create the dataset and upload each example. Saving the dataset to LangSmith lets us reuse and relate test runs over time.
import uuid
from langsmith import Client
client = Client()
dataset_name = f"Dynamic Titanic CSV {uuid.uuid4().hex[:4]}"
dataset = client.create_dataset(
dataset_name=dataset_name,
description="Test QA over CSV",
)
client.create_examples(
inputs=[{"question": example[0]} for example in questions],
outputs=[{"code": example[1]} for example in questions],
dataset_id=dataset.id,
)
2. Define Q&A system
With the dataset created, it's time to define our question answering system. We'll use the off-the-shelf pandas dataframe agent from LangChain for this tutorial.
First, load the titanic data into a dataframe, then create a constructor for our agent.
import pandas as pd
titanic_path = "https://raw.githubusercontent.com/jorisvandenbossche/pandas-tutorial/master/data/titanic.csv"
df = pd.read_csv(titanic_path)
from langchain_core.prompts import ChatPromptTemplate
from langchain_experimental.agents import create_pandas_dataframe_agent
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-turbo-preview", temperature=0.0)
def predict(inputs: dict):
agent = create_pandas_dataframe_agent(agent_type="openai-tools", llm=llm, df=df)
return agent.invoke({"input": inputs["question"]})
# Example run
predict({"question": "How many passengers were on the Titanic?"})
{'input': 'How many passengers were on the Titanic?', 'output': 'There were 891 passengers on the Titanic according to the dataframe.'}
3. Run Evaluation
Now it's time to define our custom evaluator. In this case we will inherit from the LabeledCriteriaEvalChain class. This evaluator takes the input, prediction, and reference label and passes them to an llm to predict whether the prediction satisfies the provided criteria, conditioned on the reference label.
Our custom evaluator will make one small change to this evaluator by dereferencing the label to inject the correct value. We do this by overwriting the _get_eval_input method. Then the LLM will see the fresh reference value.
> Reminder: We are using a CSV file to simulate a real data source here and doing an unsafe eval on to query the data source. In a real scenario it would be better to do a safe get request or something similar.
from typing import Optional
from langchain.evaluation.criteria.eval_chain import LabeledCriteriaEvalChain
class CustomCriteriaEvalChain(LabeledCriteriaEvalChain):
def _get_eval_input(
self,
prediction: str,
reference: Optional[str],
input: Optional[str],
) -> dict:
# The parent class validates the reference is present and combines into
# a dictionary for the llm chain.
raw = super()._get_eval_input(prediction, reference, input)
# Warning - this evaluates the code you've saved as labels in the dataset.
# Be sure that the code is correct, and refrain from executing in an
# untrusted environment or when connected to a production server.
raw["reference"] = eval(raw["reference"])
return raw
from langsmith.evaluation import LangChainStringEvaluator, evaluate
# Wrap so it can be used as a "RunEvaluator" and pipe the trace + examples
# to the underlying evaluator
base_evaluator = CustomCriteriaEvalChain.from_llm(
criteria="correctness", llm=ChatOpenAI(model="gpt-4", temperature=0.0)
)
def prepare_inputs(run, example):
return {
"prediction": next(iter(run.outputs.values())),
"reference": next(iter(example.outputs.values())),
"input": example.inputs["question"],
}
criteria_evaluator = LangChainStringEvaluator(
base_evaluator, prepare_data=prepare_inputs
)
chain_results = evaluate(
predict,
data=dataset_name,
evaluators=[criteria_evaluator],
# This agent doesn't support concurrent runs yet.
max_concurrency=1,
metadata={
"time": "T1",
},
)
/var/folders/gf/6rnp_mbx5914kx7qmmh7xzmw0000gn/T/ipykernel_80945/2037493188.py:22: UserWarning: Function evaluate_existing is in beta. chain_results = evaluate_existing(
View the evaluation results for experiment: 'sparkling-suit-54' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/8cf28879-611e-4532-9641-d593f6bffa20/compare?selectedSessions=e3e8387c-65b9-4f0e-bd20-519c28731949
0it [00:00, ?it/s]
With that evalution running, you can navigate to the linked project and review the agent's predictions and feedback scores.
4. Re-evaluate later in time.
It's safe to say the Titanic dataset has not changed in the past few minutes, but in your case, it's likely new data is coming in all the time. So long as the way to access that information has not changed, we can reuse the existing dataset!
Let's pretend that more people boarded by duplicating some rows and shuffling some stats. Then, we'll rerun the agent on the new dataset.
df_doubled = pd.concat([df, df], ignore_index=True)
df_doubled["Age"] = df_doubled["Age"].sample(frac=1).reset_index(drop=True)
df_doubled["Sex"] = df_doubled["Sex"].sample(frac=1).reset_index(drop=True)
df = df_doubled
chain_results = evaluate(
predict,
data=dataset_name,
evaluators=[criteria_evaluator],
# This agent doesn't support concurrent runs yet.
max_concurrency=1,
metadata={
"time": "T2",
},
)
/var/folders/gf/6rnp_mbx5914kx7qmmh7xzmw0000gn/T/ipykernel_80945/266341347.py:1: UserWarning: Function evaluate is in beta. chain_results = evaluate(
View the evaluation results for experiment: 'perfect-sofa-52' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/8cf28879-611e-4532-9641-d593f6bffa20/compare?selectedSessions=06bb0be8-4b77-43e3-80b3-e2c0b67900f8
0it [00:00, ?it/s]
Review the results
Now that you've tested twice on the "changing" data source, you can check out the results! If you navigate to the "dataset" page and click on the "examples" tab, you can click through different examples and see the predictions for each test run.
Below is the view of the individual dataset rows. We can click on a row to update the example or to see all predictions from different test runs on that example. Let's click on one!
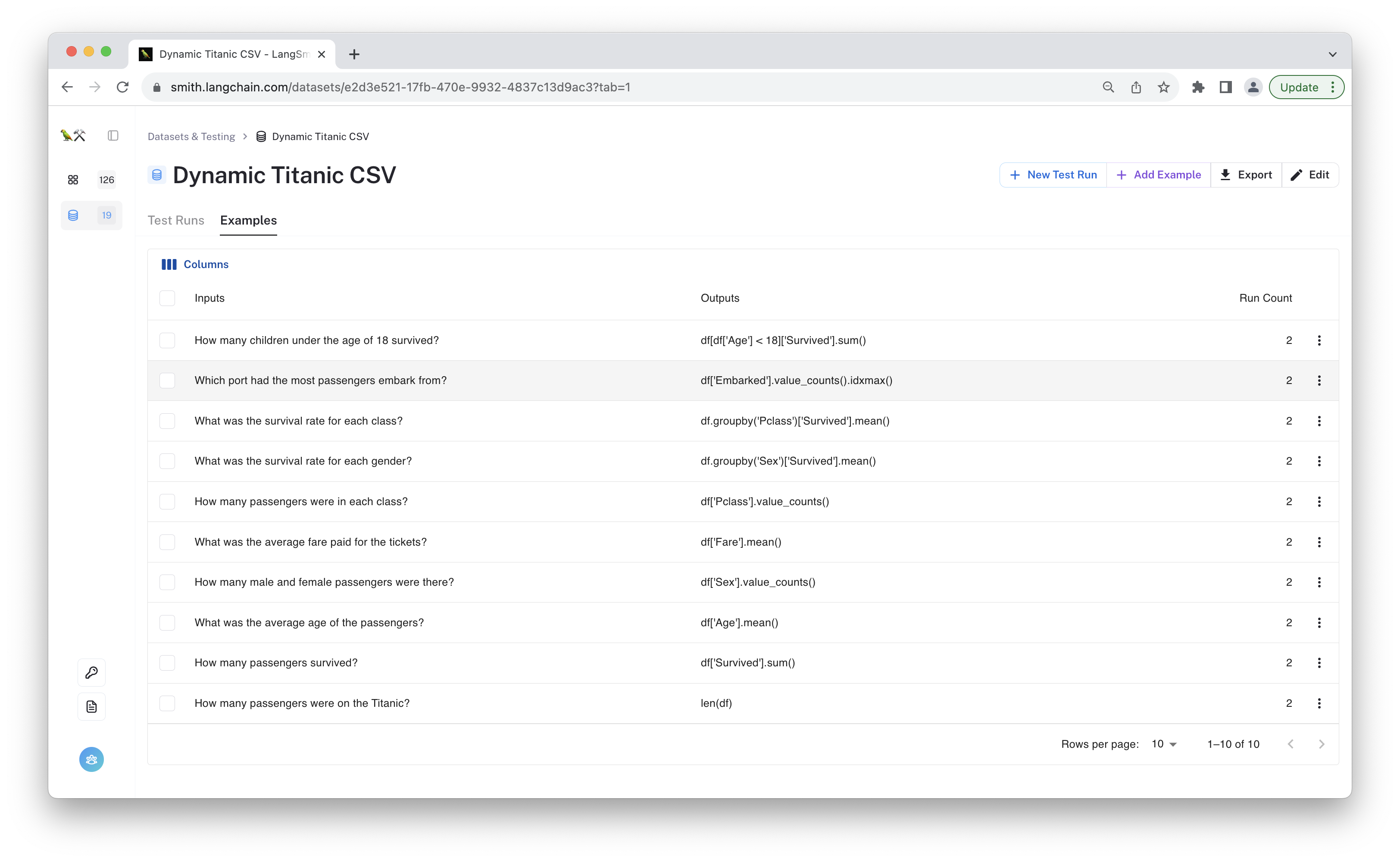
In this case, we've selected the example row with the question "How many male and female passengers were there?" The table of linked rows at the bottom of the page shows the predictions for each test run.
These are automatically assocaited whenever you call run_on_dataset.
If you look closely at the predictions, you'll see the predictions are different! At first, the agent predicted 577 male and 314 female passengers. Then for the second test run, it predicted 1154 male and 628 female passengers.
However, both test runs were marked as "correct". The values within the data source changed, but the process to retrieve the answer remained the same.
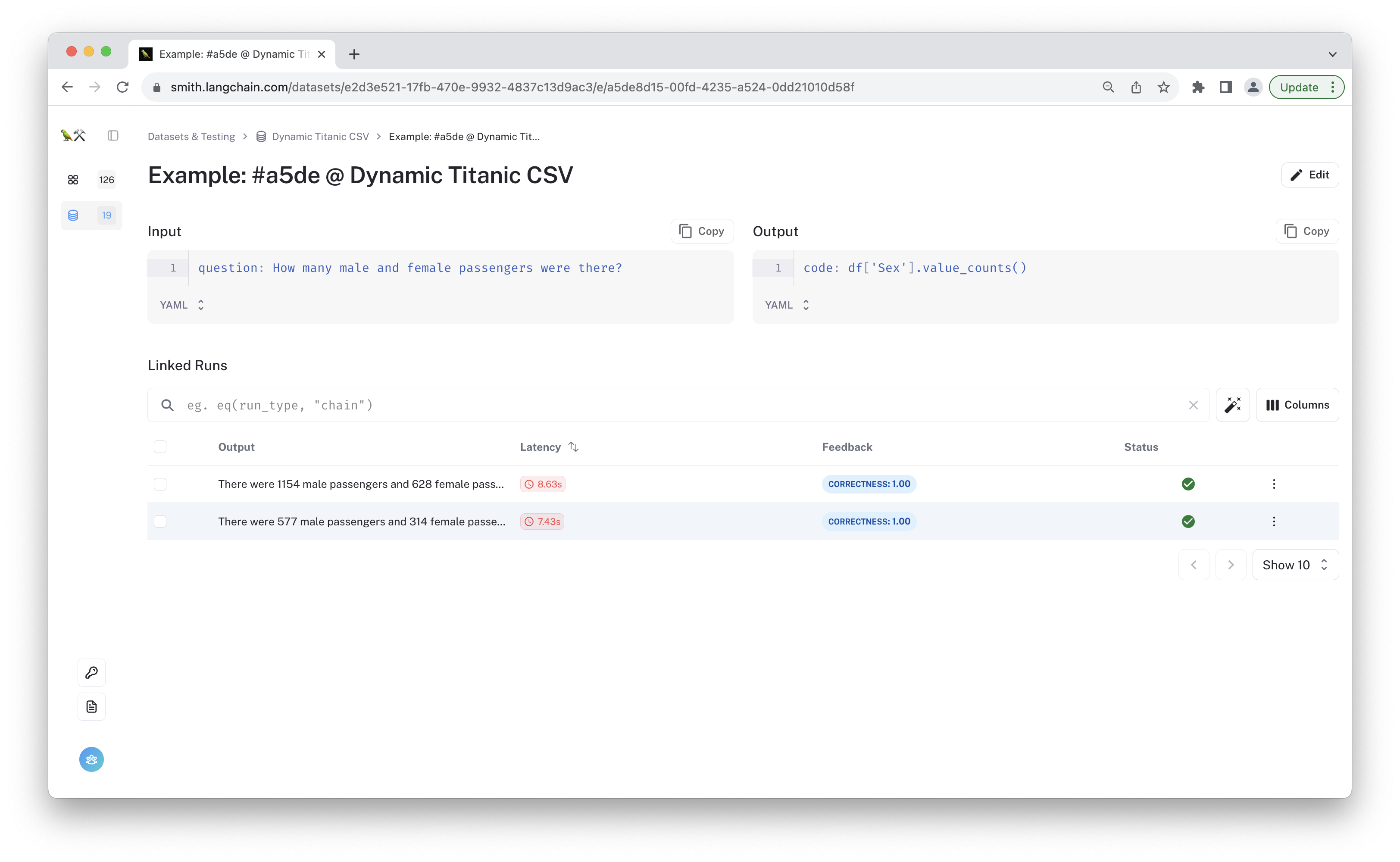
But how can you be sure the "correct" grade is reliable? Now is a good time to spot check the run trace of your custom evaluator to confirm that it is working as expected. If you see arrows on the "correctness" chips in the table, you can directly click on those to see the evaluation trace. Otherwise, you can click through to the run, navigate to the feedback tab, and then click through to find your custom evaluator's trace for that example. Below are screenshots of the retrieved values for each of the runs above.
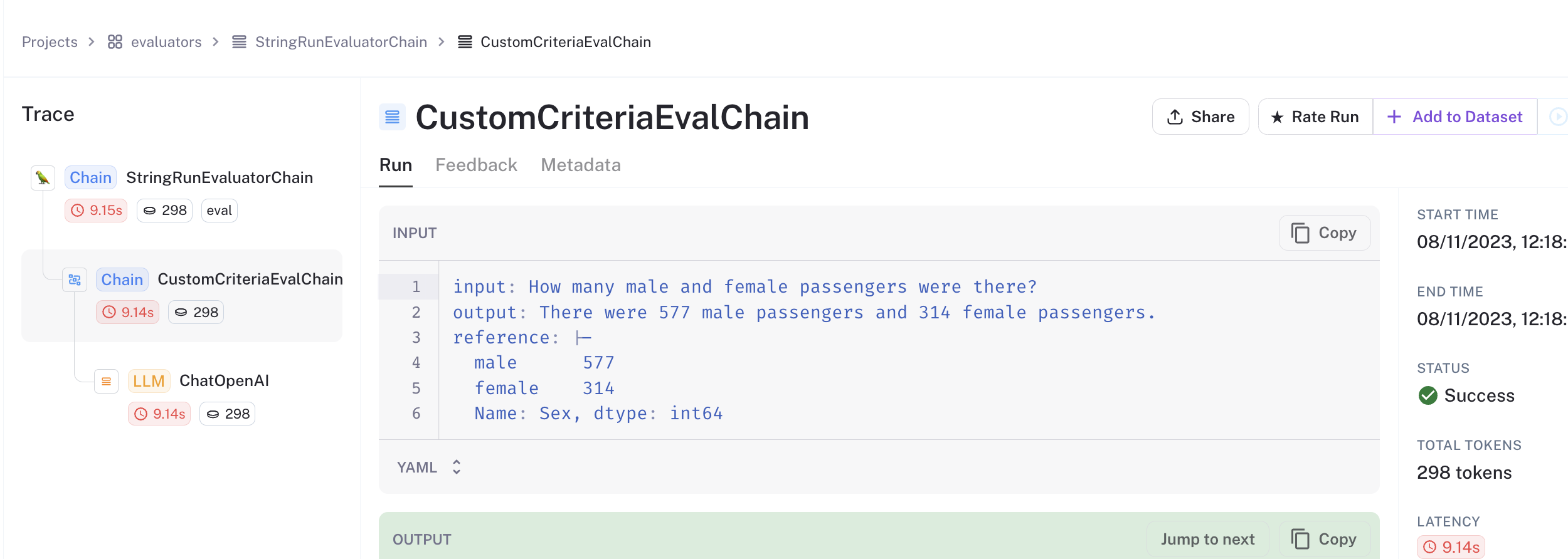
You can see that the "reference" key contains the dereferenced value from the data source. You can see that it matches the predictions from the runs above! The first one shows 577 male and 314 female passengers.
And after the dataframe was updated, the evaluator retrieved the correct value of 1154 male and 628 female passengers, which matches the predictions from the runs above!
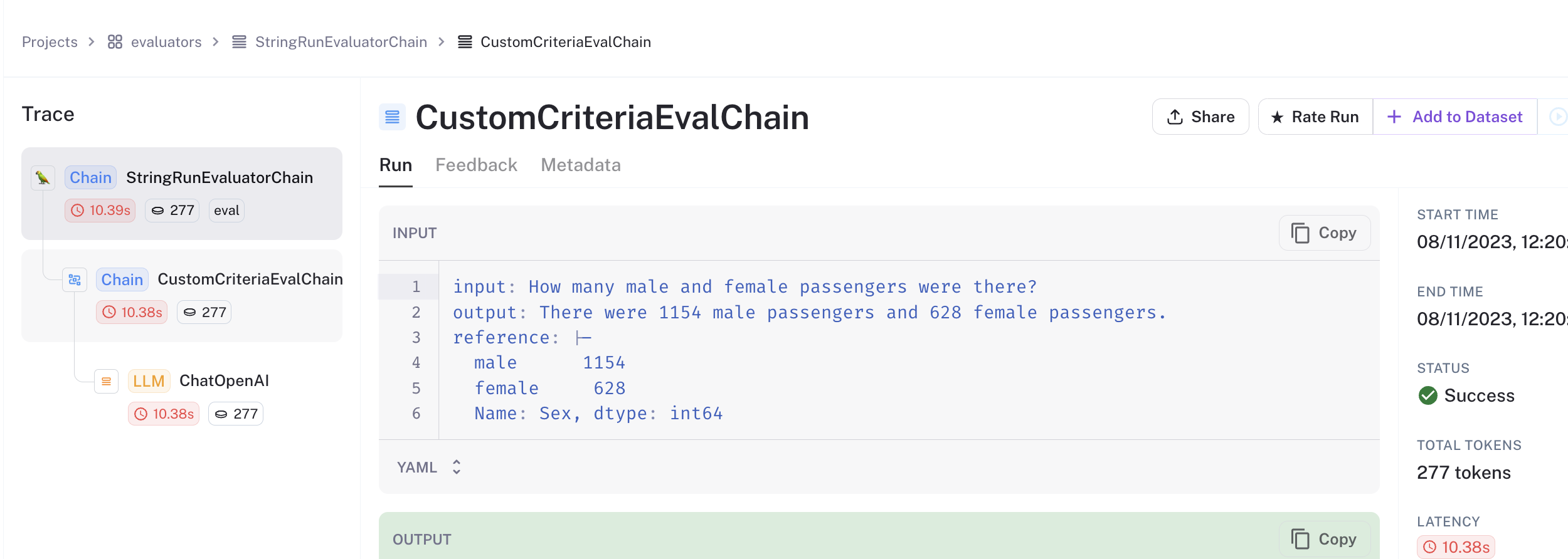
Seems to be working well!
Conclusion
In this walkthrough, you evaluated a Q&A system connected to an evolving data store. You did so by using a custom evaluator that dynamically fetches the answer based on a static reference (in this case, a code snippet).
This is just one way to approach the problem of evaluating Q&A systems when the underlying data source is changing! This approach is simple and directly tests the correctness of your system end-to-end on up-to-date data. It can help if you want to be checking in on your performance periodically.
It is less reliable if your goal is compare two different prompts or models, since the underlying data may differ. Depending on how you dereference the labels, caution and proper permissioning also is important!
Other options to evaluate your system in this scenario include:
- Freezing or mocking the data source(s) used for evaluation. You can then invest in hand-labeling periodically to make sure the data is still reprentative of the production environment.
- Testing the query generation capability of your agent directly and evaluate the equivalence of the queries. This is less "end-to-end", but it depending on how you compare, you'd avoid any potential issues caused by unsafe dereferencing.
What other approaches are you using to evaluate your Q&A system? We'd love to hear more - let us know if you have any questions or reach out at support@langchain.dev.
Thanks!