Evaluating an Extraction Chain
![]()
![]()
Structured data extraction from unstructured text is a core part of any LLM applications. Whether it's preparing structured rows for database insertion, deriving API parameters for function calling and forms, or for building knowledge graphs, the utility is present.
This walkthrough presents a method to evaluate an extraction chain. While our example dataset revolves around legal briefs, the principles and techniques laid out here are widely applicable across various domains and use-cases.
By the end of this guide, you'll be equipped to set up and evaluate extraction chains tailored to your specific needs, ensuring your applications extract information both effectively and efficiently.
Prerequisites
This walkthrough requires LangChain and Anthropic. Ensure they're installed and that you've configured the necessary API keys.
%pip install -U --quiet langchain langsmith langchain_experimental anthropic jsonschema
import os
import uuid
uid = uuid.uuid4()
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY"
os.environ["ANTHROPIC_API_KEY"] = "sk-ant-***"
# Update with your API URL if using a hosted instance of Langsmith
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
1. Create dataset
For this task, we will be filling out details about legal contracts from their context. We have prepared a mall labeled dataset for this walkthrough based on the Contract Understanding Atticus Dataset (CUAD)(link). You can explore the Contract Extraction dataset at the provided link.
from langsmith import Client
dataset_url = (
"https://smith.langchain.com/public/08ab7912-006e-4c00-a973-0f833e74907b/d"
)
dataset_name = f"Contract Extraction"
client = Client()
client.clone_public_dataset(dataset_url)
2. Define extraction chain
Our dataset inputs are quite long, so we will be testing out the experimental Anthropic Functions chain for this extraction task. This chain prompts the model to respond in XML that conforms to the provided schema.
Below, we will define the contract schema to extract
from typing import List, Optional, Union
from pydantic import BaseModel
class Address(BaseModel):
street: str
city: str
state: str
zip_code: str
country: Optional[str]
class Party(BaseModel):
name: str
address: Address
type: Optional[str]
class Section(BaseModel):
title: str
content: str
class Contract(BaseModel):
document_title: str
exhibit_number: Optional[str]
effective_date: str
parties: List[Party]
sections: List[Section]
Now we can define our extraction chain. We define it in the create_chain
from langchain import hub
from langchain.chains import create_extraction_chain
from langchain_anthropic import ChatAnthropic
from langchain_experimental.llms.anthropic_functions import AnthropicFunctions
contract_prompt = hub.pull("wfh/anthropic_contract_extraction")
extraction_subchain = create_extraction_chain(
Contract.schema(),
llm=AnthropicFunctions(model="claude-2.1", max_tokens=20_000),
prompt=contract_prompt,
)
# Dataset inputs have an "context" key, but this chain
# expects a dict with an "input" key
chain = (
(lambda x: {"input": x["context"]})
| extraction_subchain
| (lambda x: {"output": x["text"]})
)
3. Evaluate
For this evaluation, we'll utilize the JSON edit distance evaluator, which standardizes the extracted entities and then determines a normalized string edit distance between the canonical versions. It is a fast way to check for the similarity between two json objects without relying explicitly on an LLM.
import logging
# We will suppress any errors here since the documents are long
# and could pollute the notebook output
logger = logging.getLogger()
logger.setLevel(logging.CRITICAL)
from langsmith.evaluation import LangChainStringEvaluator, evaluate
res = evaluate(
chain.invoke,
data=dataset_name,
evaluators=[LangChainStringEvaluator("json_edit_distance")],
# In case you are rate-limited
max_concurrency=2,
)
/var/folders/gf/6rnp_mbx5914kx7qmmh7xzmw0000gn/T/ipykernel_72212/1408924987.py:3: UserWarning: Function evaluate is in beta.
res = evaluate(
View the evaluation results for experiment: 'ordinary-hat-82' at:
https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/fbc1a41c-7043-4b5f-b6e8-78266faac187/compare?selectedSessions=02fbe581-47ae-4c87-bcad-7a8c44e8789b
0it [00:00, ?it/s]
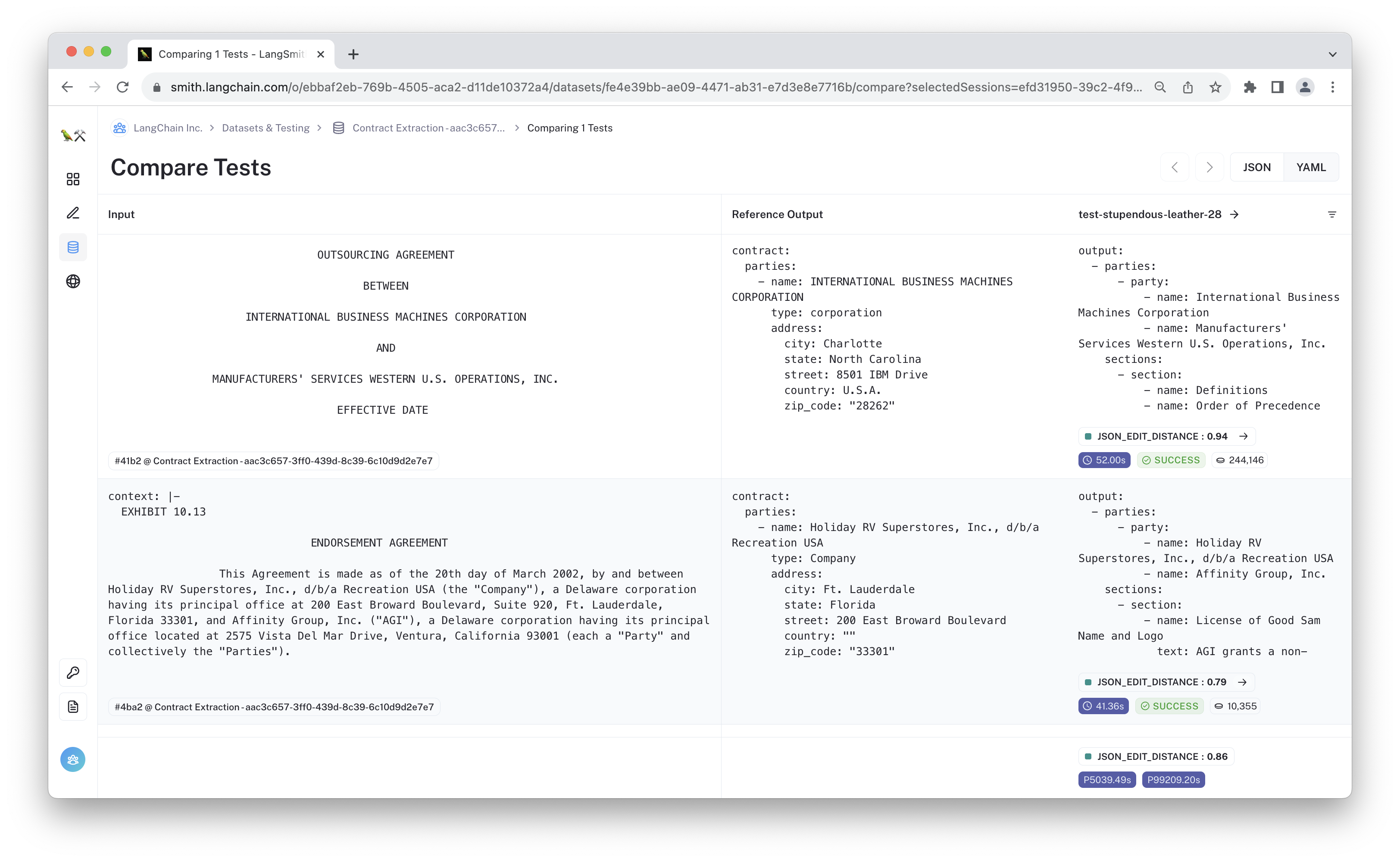
Now that you've run the evaluation, it's time to inspect the results. Go to LangSmith and click through the predictions. Where is the model failing? Can you spot any hallucinated examples? Are there improvements you'd make to the dataset?
Conclusion
In this walkthrough, we showcased a methodical approach to evaluating an extraction chain applied to template filling for legal briefs. You can use similar techniques to evaluate chains intended to return structured output.