Comparing Q&A System Outputs
![]()
![]()
The most common way to compare two models is to benchmark them both on a dataset and compare the aggregate metrics.
This approach is useful but it may filter out helpful information about the quality of the two system variants. In this case, it can be helpful to directly perform pairwise comparisons on the responses and take the resulting preference scores into consideration.
In this tutorial, we will share one way to do this in code. We will use a retrieval Q&A system over LangSmith's docs as a motivating example.
The main steps are:
- Setup
- Create a dataset of questions and answers.
- Define different versions of your chains to evaluate.
- Evaluate chains directly on a dataset using regular metrics (e.g. correctness).
- Evaluate the pairwise preferences over that dataset
In this case, we will test the impact of chunk sizes on our result quality. Let's begin!
Prerequisites
This tutorial uses OpenAI for the model, ChromaDB to store documents, and LangChain to compose the chain. To make sure the tracing and evals are set up for LangSmith, please configure your API Key appropriately.
We will also use pandas to render the results in the notebook.
import os
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY" # Update with your API key
Install the required packages. lxml and html2text are used by the document loader.
# %pip install -U "langchain[openai]" --quiet
# %pip install chromadb --quiet
# %pip install lxml --quiet
# %pip install html2text --quiet
# %pip install pandas --quiet
# %env OPENAI_API_KEY=<YOUR-API-KEY>
1. Setup
a. Create a dataset
No evaluation process is complete without a development dataset. We've hard-coded a few examples below to demonstrate the process. In general, you'll want a lot more (>100) pairs for statistically significant results. Drawing from actual user queries can be helpful to ensure better representation of the domain.
examples = [
(
"What is LangChain?",
"LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.",
),
(
"How might I query for all runs in a project?",
"client.list_runs(project_name='my-project-name'), or in TypeScript, client.ListRuns({projectName: 'my-project-anme'})",
),
(
"What's a langsmith dataset?",
"A LangSmith dataset is a collection of examples. Each example contains inputs and optional expected outputs or references for that data point.",
),
(
"How do I use a traceable decorator?",
"""The traceable decorator is available in the langsmith python SDK. To use, configure your environment with your API key,\
import the required function, decorate your function, and then call the function. Below is an example:
```python
from langsmith.run_helpers import traceable
@traceable(run_type="chain") # or "llm", etc.
def my_function(input_param):
# Function logic goes here
return output
result = my_function(input_param)
```""",
),
(
"Can I trace my Llama V2 llm?",
"So long as you are using one of LangChain's LLM implementations, all your calls can be traced",
),
(
"Why do I have to set environment variables?",
"Environment variables can tell your LangChain application to perform tracing and contain the information necessary to authenticate to LangSmith."
" While there are other ways to connect, environment variables tend to be the simplest way to configure your application.",
),
(
"How do I move my project between organizations?",
"LangSmith doesn't directly support moving projects between organizations.",
),
]
from langsmith import Client
client = Client()
import uuid
dataset_name = f"Retrieval QA Questions {str(uuid.uuid4())}"
dataset = client.create_dataset(dataset_name=dataset_name)
for q, a in examples:
client.create_example(
inputs={"question": q}, outputs={"answer": a}, dataset_id=dataset.id
)
b. Define RAG Q&A system
Our Q&A system uses a simple retriever and LLM response generator. To break that down further, the chain will be composed of:
- A VectorStoreRetriever to retrieve documents. This uses:
- An embedding model to vectorize documents and user queries for retrieval. In this case, the OpenAIEmbeddings model.
- A vectorstore, in this case we will use Chroma.
- A response generator. This uses:
- A ChatPromptTemplate to combine the query and documents.
- An LLM, in this case, the 16k token context window version of
gpt-3.5-turbovia ChatOpenAI.
We will combine them using LangChain's expression syntax.
First, load the documents to populate the vectorstore:
from langchain.document_loaders import RecursiveUrlLoader
from langchain.document_transformers import Html2TextTransformer
from langchain.text_splitter import TokenTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
api_loader = RecursiveUrlLoader("https://docs.smith.langchain.com")
doc_transformer = Html2TextTransformer()
raw_documents = api_loader.load()
transformed = doc_transformer.transform_documents(raw_documents)
def create_retriever(transformed_documents, text_splitter):
documents = text_splitter.split_documents(transformed_documents)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents, embeddings)
return vectorstore.as_retriever(search_kwargs={"k": 4})
/Users/wfh/.pyenv/versions/3.11.2/lib/python3.11/site-packages/bs4/builder/init.py:545: XMLParsedAsHTMLWarning: It looks like you're parsing an XML document using an HTML parser. If this really is an HTML document (maybe it's XHTML?), you can ignore or filter this warning. If it's XML, you should know that using an XML parser will be more reliable. To parse this document as XML, make sure you have the lxml package installed, and pass the keyword argument features="xml" into the BeautifulSoup constructor.
warnings.warn(
Next up, we'll define the chain. Since we are going to vary the retriever parameters, our constructor will take the retriever as an argument.
from datetime import datetime
from operator import itemgetter
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
def create_chain(retriever):
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful documentation Q&A assistant, trained to answer"
" questions from LangSmith's documentation."
" LangChain is a framework for building applications using large language models."
"\nThe current time is {time}.\n\nRelevant documents will be retrieved in the following messages.",
),
("system", "{context}"),
("human", "{question}"),
]
).partial(time=str(datetime.now()))
model = ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0)
response_generator = prompt | model | StrOutputParser()
chain = (
# The runnable map here routes the original inputs to a context and a question dictionary to pass to the response generator
{
"context": itemgetter("question")
| retriever
| (lambda docs: "\n".join([doc.page_content for doc in docs])),
"question": itemgetter("question"),
}
| response_generator
)
return chain
With the documents prepared, and the chain constructor ready, it's time to create and evaluate our chains. We will vary the split size and overlap to evaluate its impact on the response quality.
text_splitter = TokenTextSplitter(
model_name="gpt-3.5-turbo",
chunk_size=2000,
chunk_overlap=200,
)
retriever = create_retriever(transformed, text_splitter)
chain_1 = create_chain(retriever)
# We will shrink both the chunk size and overlap
text_splitter_2 = TokenTextSplitter(
model_name="gpt-3.5-turbo",
chunk_size=500,
chunk_overlap=50,
)
retriever_2 = create_retriever(transformed, text_splitter_2)
chain_2 = create_chain(retriever_2)
c. Evaluate the chains
At this point, we are still going through the regular development -> evaluation process. We have two candidates and will evaluate them with a correctness evaluator from LangChain. By running run_on_dataset, we will generate predicted answers to each question in the dataset and log feedback from the evaluator for that data point.
from langchain.smith import RunEvalConfig
eval_config = RunEvalConfig(
# We will use the chain-of-thought Q&A correctness evaluator
evaluators=["cot_qa"],
)
results = client.run_on_dataset(
dataset_name=dataset_name, llm_or_chain_factory=chain_1, evaluation=eval_config
)
project_name = results["project_name"]
View the evaluation results for project 'test-new-goat-73' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/8097fed2-ca97-42b6-b71a-a24fe5e7c9d6 [------------------------------------------------->] 7/7
results_2 = client.run_on_dataset(
dataset_name=dataset_name, llm_or_chain_factory=chain_2, evaluation=eval_config
)
project_name_2 = results_2["project_name"]
View the evaluation results for project 'test-large-stone-98' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/projects/p/4f3b1676-741b-4fb1-bfc1-46ca630ac160 [------------------------------------------------->] 7/7
Now you should have two test run projects over the same dataset. If you click on one, it should look something like the following:
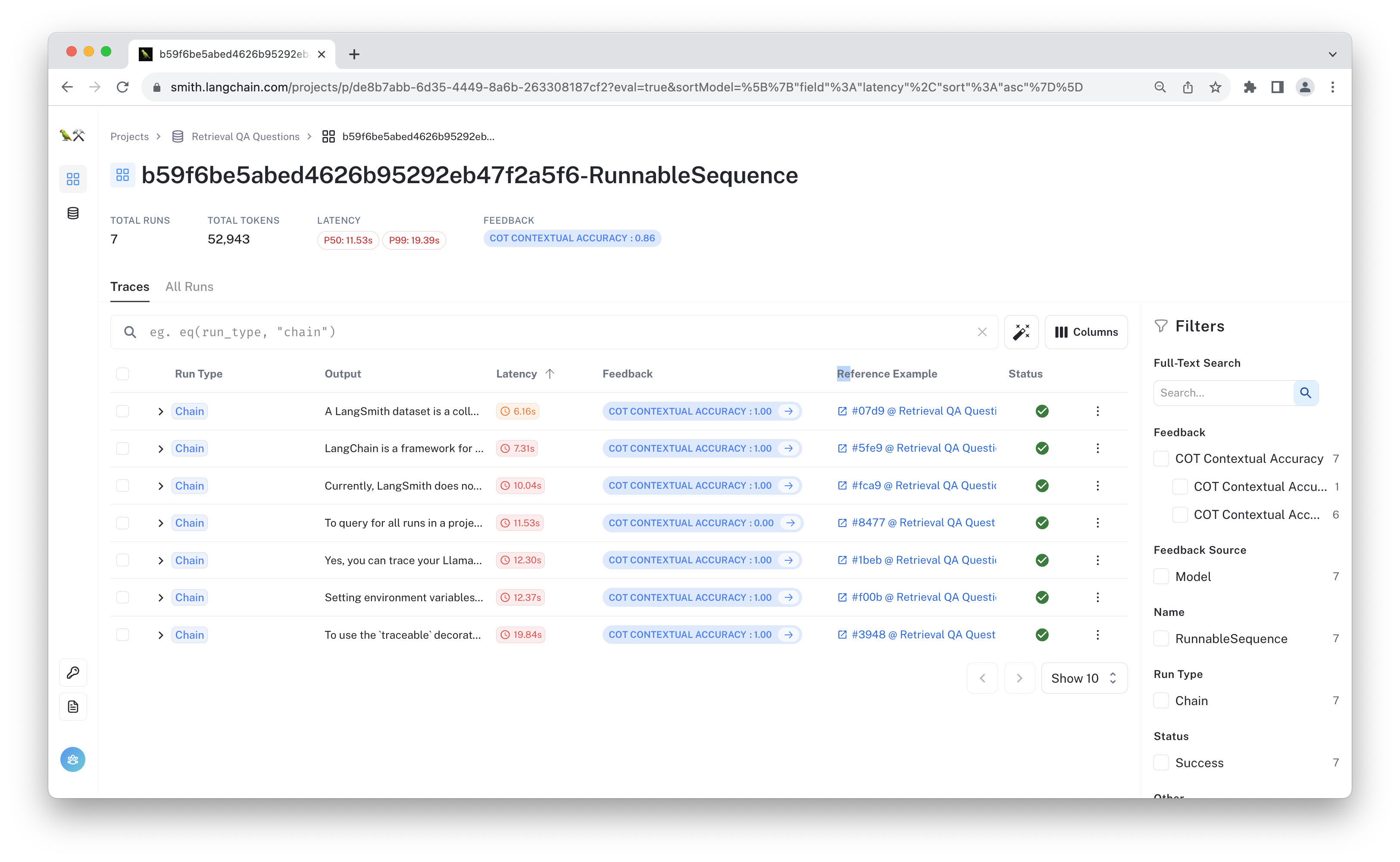
You can look at the aggregate results here and for the other project to compare them. You could also view them in a dataframe:
import pandas as pd
runs_1 = list(client.list_runs(project_name=project_name, execution_order=1))
runs_2 = list(client.list_runs(project_name=project_name_2, execution_order=1))
def get_project_df(runs):
return pd.DataFrame(
[
{**run.outputs, **{k: v.get("avg") for k, v in run.feedback_stats.items()}}
for run in runs
],
index=[run.reference_example_id for run in runs],
)
runs_1_df = get_project_df(runs_1)
runs_2_df = get_project_df(runs_2)
joined_df = runs_1_df.join(runs_2_df, lsuffix="_1", rsuffix="_2")
columns_1 = [col for col in joined_df.columns if col.endswith("_1")]
columns_2 = [col for col in joined_df.columns if col.endswith("_2")]
new_columns_order = [col for pair in zip(columns_1, columns_2) for col in pair]
joined_df = joined_df[new_columns_order]
joined_df
| output_1 | output_2 | COT Contextual Accuracy_1 | COT Contextual Accuracy_2 | 04a95258-4999-4abd-b1c3-0c5214130579 | 198d7039-72bc-4376-907a-87066d85275b | ea7b3f78-020e-410b-8e7b-bfdfa681a386 | 3cdd7b83-9a60-4c1b-b30b-dfa3fae69740 | 5ec65a7d-70de-4494-b780-139550e301e5 | 7b74f055-3a2e-4b6f-a3d1-45eecfddcc63 | f23253e5-c537-43f0-8059-38153090a884
--- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ---
LangChain is an open-source framework for buil... | LangChain is an open-source framework for buil... | 1.0 | 1.0
To query for all runs in a project, you can us... | To query for all runs in a project using LangS... | 0.0 | 0.0
A LangSmith dataset is a collection of input-o... | A LangSmith dataset refers to a collection of ... | 1.0 | 1.0
To use a traceable decorator in LangSmith, you... | To use the traceable decorator in LangSmith,... | 0.0 | 0.0
Yes, you can trace your Llama V2 LLM using Lan... | Yes, you can trace your Llama V2 LLM using Lan... | 1.0 | 1.0
To move a project between organizations in Lan... | To move a project between organizations in Lan... | 0.0 | 0.0
At LangChain, setting environment variables is... | Setting environment variables is necessary in ... | 1.0 | 1.0
It looks like the benchmark performance is similar, so let's move on to the pairwise comparison.
Compare in LangSmith
Navigate to the "Retrieval QA Questions" dataset in LangSmith, select the two tests you just completed, then click "Compare."
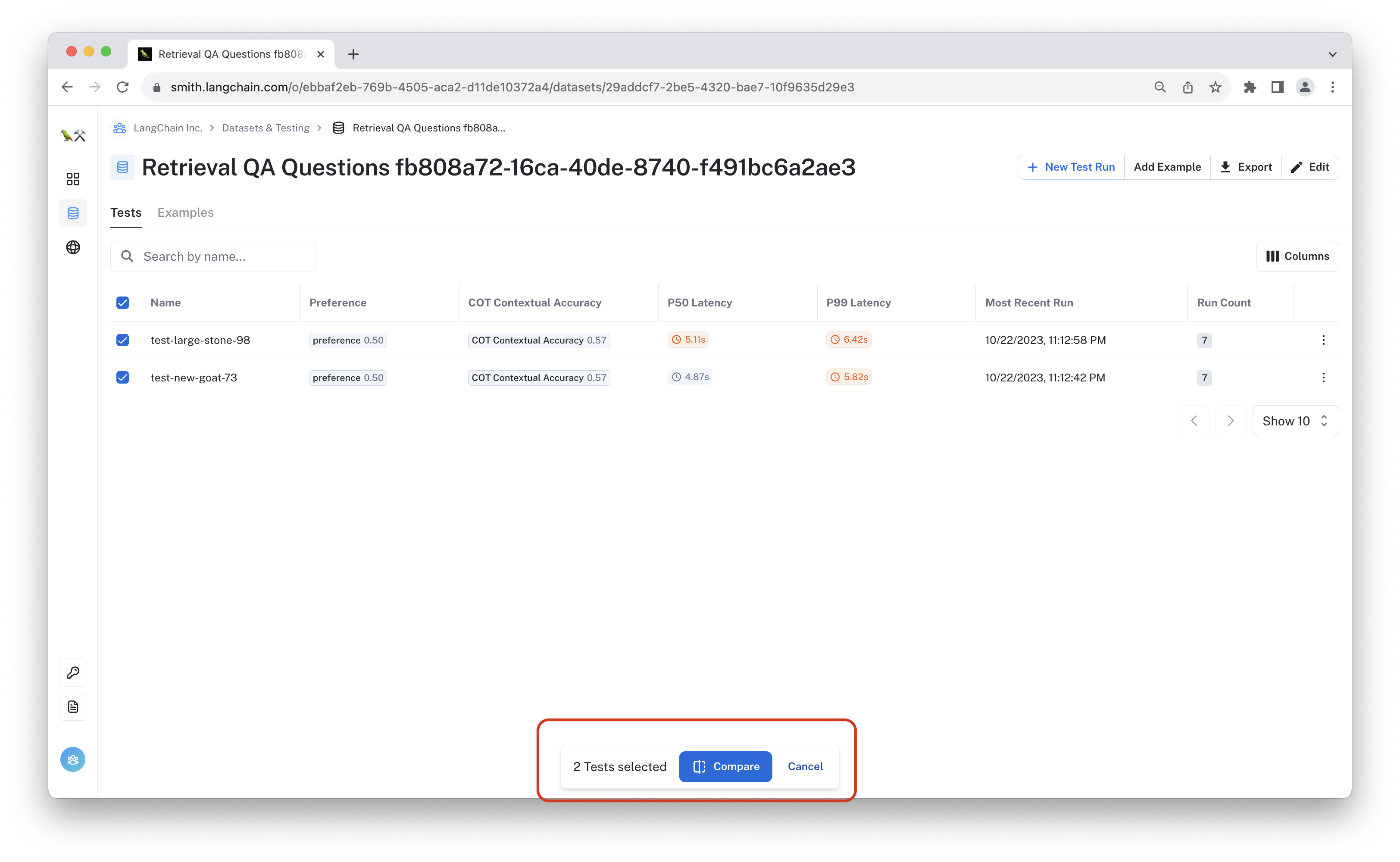
From this view, you can manually review and compare the results. You can even filter by initial scores to select outputs where the grades differ.
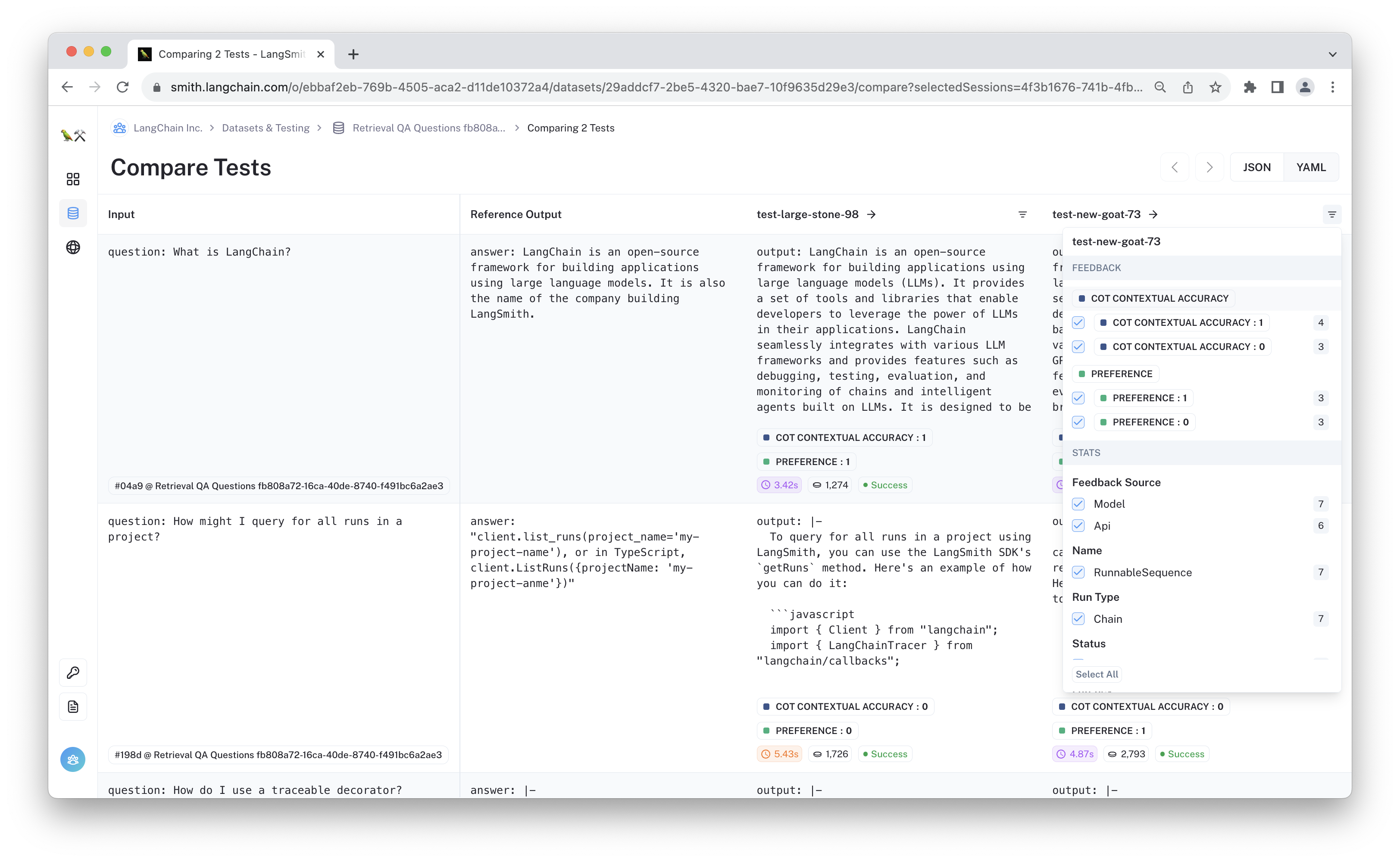
Manual comparison is incredibly useful, but it's hard to do this on every test run. Below, we will show how to use an LLM to directly compare the results.
2. Pairwise Evaluation
Suppose both approaches return similar scores when evaluated in isolation.
We can run a pairwise evaluator to see how try to predict preferred outputs. We will first define a couple helper functions to run the evaluator on each prediction pair. Let's break this function down:
- The function accepts a dataset example and loads each model's predictions on that data point.
- It then randomizes the order of the predictions and calls the evaluator. This is done to aveage out the impact of any ordering bias in the evaluator LLM.
- Once the evaluation result is returned, we check it to make sure it is valid and then log feedback for both models.
Once this is complete, the values are all returned so we can display them in a table in the notebook below.
import random
import logging
def _get_run_and_prediction(example_id, project_name):
run = next(
client.list_runs(
reference_example_id=example_id,
project_name=project_name,
execution_order=1,
)
)
prediction = next(iter(run.outputs.values()))
return run, prediction
def _log_feedback(run_ids):
for score, run_id in enumerate(run_ids):
client.create_feedback(run_id, key="preference", score=score)
def predict_preference(example, project_a, project_b, eval_chain):
example_id = example.id
print(example)
run_a, pred_a = _get_run_and_prediction(example_id, project_a)
run_b, pred_b = _get_run_and_prediction(example_id, project_b)
input_, answer = example.inputs["question"], example.outputs["answer"]
result = {"input": input_, "answer": answer, "A": pred_a, "B": pred_b}
# Flip a coin to average out persistent positional bias
if random.random() < 0.5:
result["A"], result["B"] = result["B"], result["A"]
run_a, run_b = run_b, run_a
try:
eval_res = eval_chain.evaluate_string_pairs(
prediction=result["A"],
prediction_b=result["B"],
input=input_,
reference=answer,
)
except Exception as e:
logging.warning(e)
return result
if eval_res["value"] is None:
return result
preferred_run = (run_a.id, "A") if eval_res["value"] == "A" else (run_b.id, "B")
runner_up_run = (run_b.id, "B") if eval_res["value"] == "A" else (run_a.id, "A")
_log_feedback((runner_up_run[0], preferred_run[0]))
result["Preferred"] = preferred_run[1]
return result
For this example, we will use the labeled_pairwise_string evaluator from LangChain off-the-shelf. By default, instructs the evaluation llm to choose the preference based on helpfulness, relevance, correctness, and depth of thought. In your case, you will likely want to customize the criteria used!
For more information on how to configure it, check out the Labeled Pairwise String Evaluator documentation and inspect the resulting traces when running this notebook.
from langchain.evaluation import load_evaluator
pairwise_evaluator = load_evaluator("labeled_pairwise_string")
import functools
from langchain.schema.runnable import RunnableLambda
eval_func = functools.partial(
predict_preference,
project_a=project_name,
project_b=project_name_2,
eval_chain=pairwise_evaluator,
)
# We will wrap in a lambda to take advantage of its default `batch` convenience method
runnable = RunnableLambda(eval_func)
examples = list(client.list_examples(dataset_id=dataset.id))
values = runnable.batch(examples)
dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': 'How do I move my project between organizations?'} outputs={'answer': "LangSmith doesn't directly support moving projects between organizations."} id=UUID('7b74f055-3a2e-4b6f-a3d1-45eecfddcc63') created_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 588671) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 645828) runs=[]dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': 'How do I use a traceable decorator?'} outputs={'answer': 'The traceable decorator is available in the langsmith python SDK. To use, configure your environment with your API key,import the required function, decorate your function, and then call the function. Below is an example:\n```python\nfrom langsmith.run_helpers import traceable\n@traceable(run_type="chain") # or "llm", etc.\ndef my_function(input_param):\n # Function logic goes here\n return output\nresult = my_function(input_param)\n```'} id=UUID('3cdd7b83-9a60-4c1b-b30b-dfa3fae69740') created_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 266140) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 325103) runs=[] dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': 'What is LangChain?'} outputs={'answer': 'LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.'} id=UUID('04a95258-4999-4abd-b1c3-0c5214130579') created_at=datetime.datetime(2023, 10, 23, 6, 12, 26, 903170) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 26, 963093) runs=[] dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': 'Can I trace my Llama V2 llm?'} outputs={'answer': "So long as you are using one of LangChain's LLM implementations, all your calls can be traced"} id=UUID('5ec65a7d-70de-4494-b780-139550e301e5') created_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 363825) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 435359) runs=[]
dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': 'Why do I have to set environment variables?'} outputs={'answer': 'Environment variables can tell your LangChain application to perform tracing and contain the information necessary to authenticate to LangSmith. While there are other ways to connect, environment variables tend to be the simplest way to configure your application.'} id=UUID('f23253e5-c537-43f0-8059-38153090a884') created_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 485675) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 547965) runs=[] dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': "What's a langsmith dataset?"} outputs={'answer': 'A LangSmith dataset is a collection of examples. Each example contains inputs and optional expected outputs or references for that data point.'} id=UUID('ea7b3f78-020e-410b-8e7b-bfdfa681a386') created_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 120041) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 213155) runs=[] dataset_id=UUID('29addcf7-2be5-4320-bae7-10f9635d29e3') inputs={'question': 'How might I query for all runs in a project?'} outputs={'answer': "client.list_runs(project_name='my-project-name'), or in TypeScript, client.ListRuns({projectName: 'my-project-anme'})"} id=UUID('198d7039-72bc-4376-907a-87066d85275b') created_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 26145) modified_at=datetime.datetime(2023, 10, 23, 6, 12, 27, 80568) runs=[]
By running the function above, the "preference" feedback was automatically logged to the test projects you created in step 3. Below is a view of the same test run as before with the preference scores added. This model seems to be less preferred than the other!
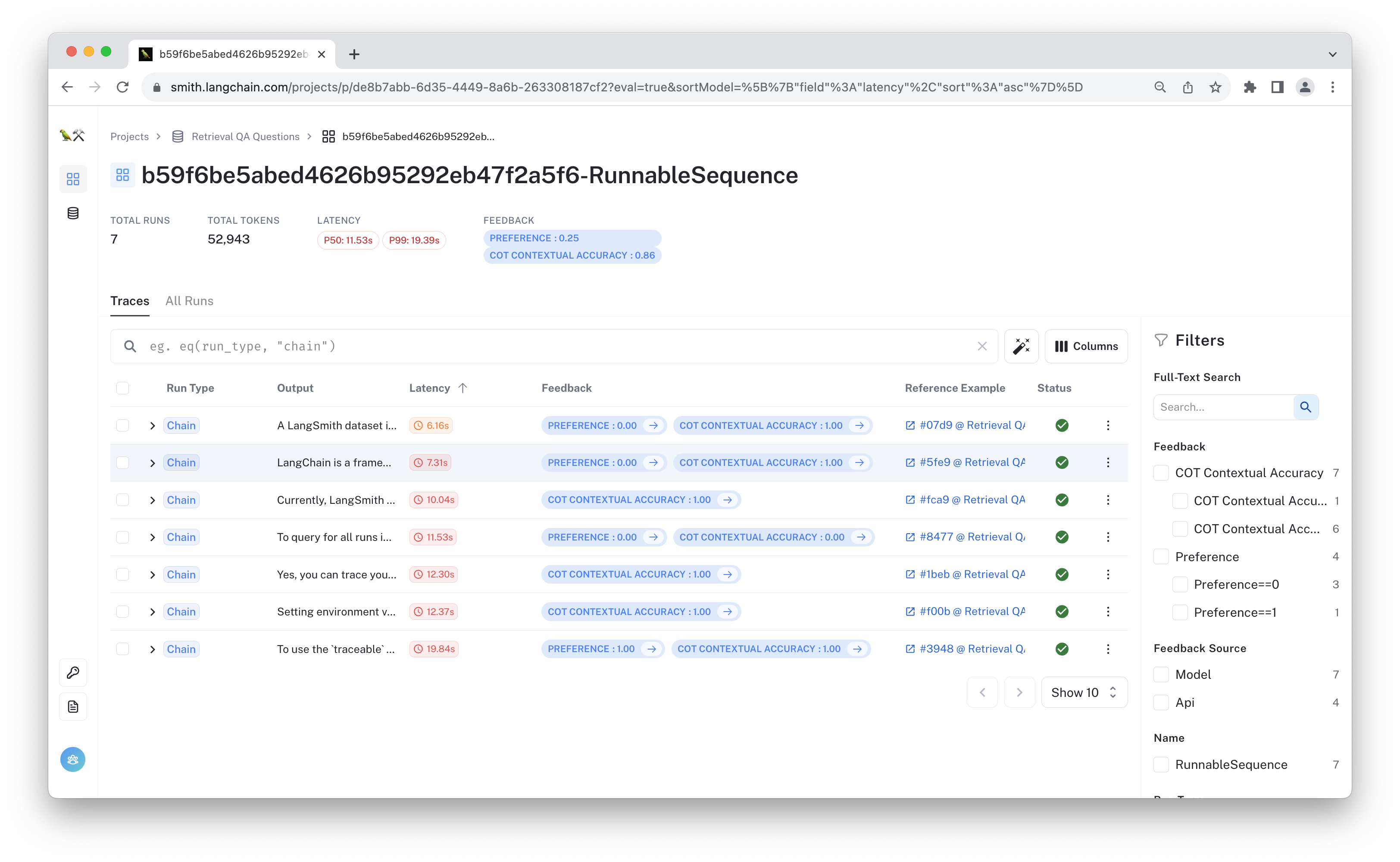
The predict_preference function we wrote above is set up to not log feedback in the case of a tie, meaning some of the examples do not have a corresponding preference score. You can adjust this behavior as you see fit.
You can also view the feedback results for the other test run in the app to see how well the evaluator's results match your expectations.
import pandas as pd
df = pd.DataFrame(values)
df.head(10)
| input | answer | A | B | Preferred | 0 | 1 | 2 | 3 | 4 | 5 | 6
--- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ---
How do I move my project between organizations? | LangSmith doesn't directly support moving proj... | To move a project between organizations in Lan... | To move a project between organizations in Lan... | NaN
Why do I have to set environment variables? | Environment variables can tell your LangChain ... | Setting environment variables is necessary in ... | At LangChain, setting environment variables is... | A
Can I trace my Llama V2 llm? | So long as you are using one of LangChain's LL... | Yes, you can trace your Llama V2 LLM using Lan... | Yes, you can trace your Llama V2 LLM using Lan... | B
How do I use a traceable decorator? | The traceable decorator is available in the la... | To use the traceable decorator in LangSmith,... | To use a traceable decorator in LangSmith, you... | A
What's a langsmith dataset? | A LangSmith dataset is a collection of example... | A LangSmith dataset is a collection of input-o... | A LangSmith dataset refers to a collection of ... | A
How might I query for all runs in a project? | client.list_runs(project_name='my-project-name... | To query for all runs in a project, you can us... | To query for all runs in a project using LangS... | A
What is LangChain? | LangChain is an open-source framework for buil... | LangChain is an open-source framework for buil... | LangChain is an open-source framework for buil... | A
Conclusion
In this walkthrough, you compared two versions of a RAG Q&A chain by predicting preference scores for each pair of predictions. This approach is one way to automatically compare two versions of a chain that can give additional context beyond regular benchmarking.
There are many related ways to evaluate preferences! Here, we used binary choices to compare the two models and only evaluated once, but you may get better results by trying one of the following approaches:
- Evaluate multiple times in each position and returning a win rate
- Ensemble evaluators
- Instruct the model to output continuous scores
- Instruct the model to use a different prompt strategy than chain of thought
For more information on measuring the reliability of this and other approaches, you can check out the evaluations examples in the LangChain repo.