Evaluate a Conversational Chat Bot
![]()
![]()
Chat bots, designed to assist users or provide entertainment, typically engage in multiple conversational turns in any given chat session. Over extended interactions, there is potential for the quality of the LLM responses to diminish. This can manifest as difficulty in recalling earlier conversation details, improper interaction with external resources (if available), or repetitive and uninspired responses. If your current offline evaluations focus solely on individual question-answer pairs, such nuances may go unnoticed.
This walkthrough guides you in creating a dataset to evaluate chatbots within multi-turn conversations. Rather than complicate the evaluation with simulation-based methods, the technique outlined below simplifies the process: we treat each data point as an individual dialogue turn. The image below shows two rows from the example dataset used in this walkthrough. The user's question would be difficult to comprehend when taken out of context, but the chat history provides enough information to cue the bot in on what should be included.
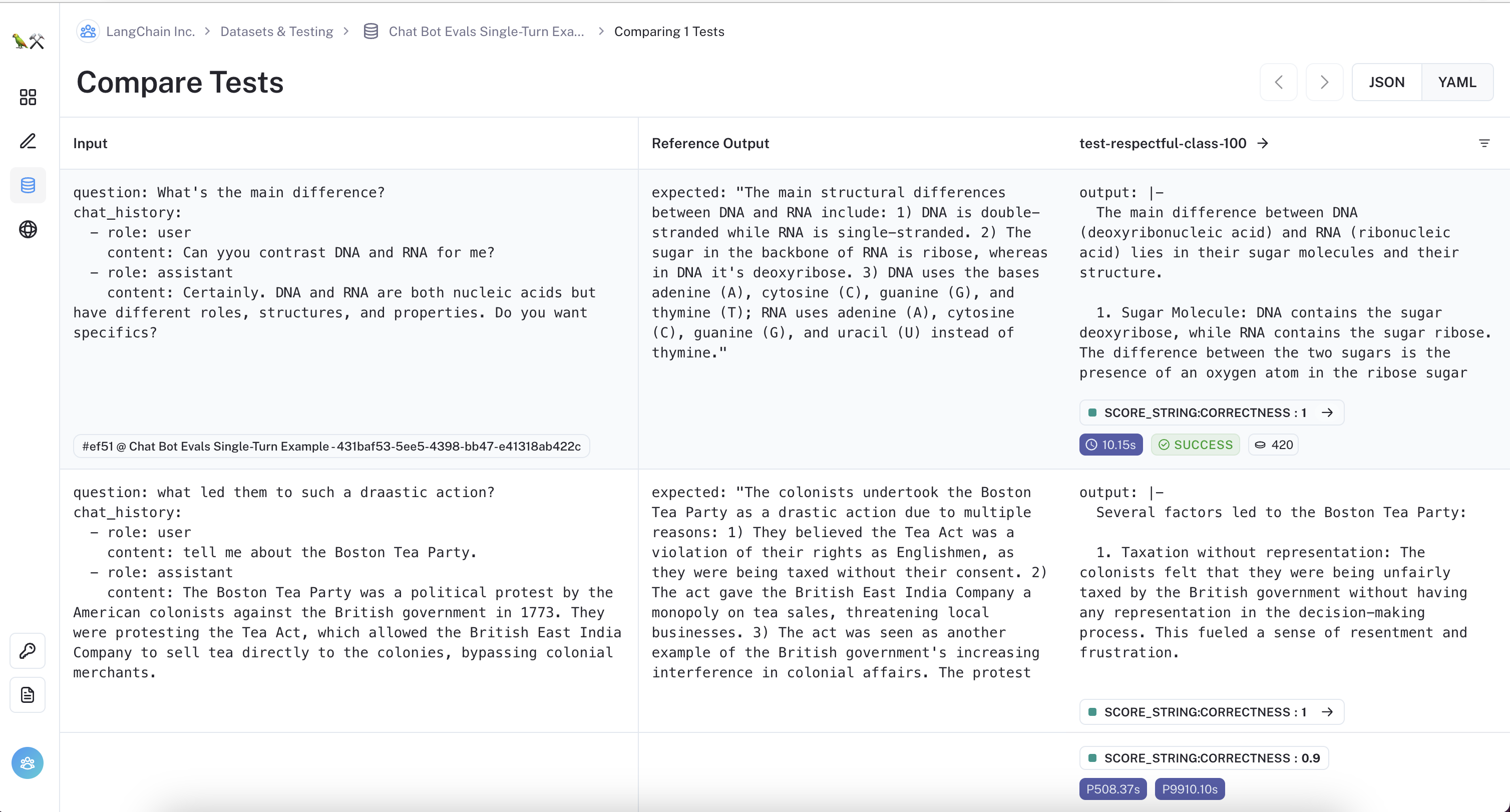
Evaluating each dialogue turn independently provides an additional benefit: if the examples are sampled from different stages of actual dialogues, they effectively capture and represent typical scenarios your bot should be able to handle well.
This notebook provides a concise overview of the process. Let's get started!
Prerequisites
This walkthrough uses LangChain and OpenAI. Install these packages below and configure your API keys accordingly.
%pip install -U langchain_openai langsmith
import os
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY"
os.environ["OPENAI_API_KEY"] = "YOUR API KEY"
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
import uuid
from langsmith import Client
uid = uuid.uuid4()
client = Client()
1. Create dataset
The key component of a multi-turn dialogue dataset is a list of conversational "turns". For each dataset example row, we will evaluate how well the chat bot can respond, taking the conversation history into account.
To accomplish his, we will make a dataset using a list of chat message dictionaries. We have factored out the "incoming" user query as a separate field.
examples = [
{
"inputs": {
"question": "How does that apply?",
"chat_history": [
{
"role": "user",
"content": "I’m trying tto uunderstand instein’s theory.",
},
{
"role": "assistant",
"content": "Which one? He's known for several theories.",
},
{"role": "user", "content": "Thee one about time and spae."},
{
"role": "assistant",
"content": "Ah, you're referring to the theory of relativity. There are two parts: special and general. Which one?",
},
],
},
"outputs": {
"expected": "Special relativity, proposed by Einstein in 1905, deals with objects in uniform motion, especially those moving at the speed of light. It introduced the idea that time and space are relative and can change in relation to each other. For instance, time can appear to move slower for an object moving close to the speed of light."
},
},
{
"inputs": {
"question": "What's the main difference?",
"chat_history": [
{"role": "user", "content": "Can yyou contrast DNA and RNA for me?"},
{
"role": "assistant",
"content": "Certainly. DNA and RNA are both nucleic acids but have different roles, structures, and properties. Do you want specifics?",
},
],
},
"outputs": {
"expected": "The main structural differences between DNA and RNA include: 1) DNA is double-stranded while RNA is single-stranded. 2) The sugar in the backbone of RNA is ribose, whereas in DNA it's deoxyribose. 3) DNA uses the bases adenine (A), cytosine (C), guanine (G), and thymine (T); RNA uses adenine (A), cytosine (C), guanine (G), and uracil (U) instead of thymine."
},
},
{
"inputs": {
"question": "what led them to such a draastic action?",
"chat_history": [
{"role": "user", "content": "tell me about the Boston Tea Party."},
{
"role": "assistant",
"content": "The Boston Tea Party was a political protest by the American colonists against the British government in 1773. They were protesting the Tea Act, which allowed the British East India Company to sell tea directly to the colonies, bypassing colonial merchants.",
},
],
},
"outputs": {
"expected": "The colonists undertook the Boston Tea Party as a drastic action due to multiple reasons: 1) They believed the Tea Act was a violation of their rights as Englishmen, as they were being taxed without their consent. 2) The act gave the British East India Company a monopoly on tea sales, threatening local businesses. 3) The act was seen as another example of the British government's increasing interference in colonial affairs. The protest was a way to show their strong opposition to British policies."
},
},
{
"inputs": {
"question": "thats a scary one. can it be avoideed?",
"chat_history": [
{"role": "user", "content": "I'm learning bout genetic disorders."},
{
"role": "assistant",
"content": "Genetic disorders are diseases caused by abnormalities in an individual's DNA. They can be inherited or result from mutations. One common one is Huntington's disease.",
},
],
},
"outputs": {
"expected": "Huntington's disease is a hereditary genetic disorder caused by a mutation in the HTT gene. If a person inherits the defective gene, they will eventually develop the disease. Currently, there's no cure for Huntington's, but its onset can be delayed with treatment. Genetic counseling and testing can help prospective parents understand the risks of passing the mutation to their offspring."
},
},
{
"inputs": {
"question": "Which one?",
"chat_history": [
{
"role": "user",
"content": "I'm confused aboutt stars. what even aaaare they?",
},
{
"role": "assistant",
"content": "Stars are celestial bodies made mostly of hydrogen and helium. They generate light and heat through nuclear fusion in their cores.",
},
{
"role": "user",
"content": "there''s a classification based on theirbrightness, right?",
},
{
"role": "assistant",
"content": "Yes",
},
],
},
"outputs": {
"expected": "Yes, stars are classified based on their brightness using a system called the Hertzsprung-Russell (H-R) diagram. In this diagram, stars are categorized into main-sequence stars, giants, supergiants, and white dwarfs, based on their luminosity and temperature. The Sun, for instance, is a main-sequence star."
},
},
]
dataset_name = f"Chat Bot Evals Single-Turn Example - {uid}"
dataset = client.create_dataset(dataset_name)
client.create_examples(
inputs=[e["inputs"] for e in examples],
outputs=[e["outputs"] for e in examples],
dataset_id=dataset.id,
)
Step 2: Define chat bot
For this tutorial, our simple chat bot formats the messages for an LLM and responds with the resulting content without consulting any external resources.
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.schema.output_parser import StrOutputParser
from langchain_openai import ChatOpenAI
# An example chain
chain = (
ChatPromptTemplate.from_messages(
[
("system", "You are a helpful tutor AI."),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
]
)
| ChatOpenAI(model="gpt-3.5-turbo")
| StrOutputParser()
)
Step 3: Evaluate
Now that we have defined our dataset and chat bot, it's time to run the evaluation.
We will pass a constructor in to the run_on_dataset function to create a new instance
of our bot for each dataset example. This also includes some mapping logic to prepare
the data for the bot itself.
from langchain.adapters.openai import convert_openai_messages
from langsmith.evaluation import LangChainStringEvaluator, evaluate
from langsmith.schemas import Example, Run
def predict(inputs: dict):
# Add a step to convert the data from the dataset to a form the chain can consume
return chain.invoke(
{
"input": inputs["question"],
"chat_history": convert_openai_messages(inputs["chat_history"]),
}
)
def format_evaluator_inputs(run: Run, example: Example):
return {
"input": example.inputs["question"],
"prediction": next(iter(run.outputs.values())),
"reference": example.outputs["expected"],
}
correctness_evaluator = LangChainStringEvaluator(
"labeled_score_string",
config={"criteria": "correctness", "normalize_by": 10},
prepare_data=format_evaluator_inputs,
)
results = evaluate(
predict,
data=dataset_name,
experiment_prefix="Chat Single Turn",
evaluators=[correctness_evaluator],
metadata={"model": "gpt-3.5-turbo"},
)
/var/folders/gf/6rnp_mbx5914kx7qmmh7xzmw0000gn/T/ipykernel_66655/886609067.py:30: UserWarning: Function evaluate is in beta.
results = evaluate(
View the evaluation results for experiment: 'Chat Single Turn:bc7b047' at:
https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/c7f90d0a-73cd-40dc-9638-4191e8114092/compare?selectedSessions=6646f09e-7321-468b-9bef-32fcbd71c1f6
0it [00:00, ?it/s]
Conclusion
We've covered the steps to create a conversational dataset to measure your chat bot's ability to handle conversation history.
Effective evaluation focuses on ensuring the bot maintains consistent and accurate interactions across turns. With the methods outlined here, you're set up to measure and improve this aspect of your chat bot's performance.