Prompt Bootstrapping with Human Feedback
Prompt engineering isn't always the most fun, especially when it comes to tasks where metrics are hard to defined. Crafting a prompt is often an iterative process, and it can be hard to get over the initial "cold start problem" of creating good prompts and datasets.
Turns out LLMs can do a decent job at prompt engineering, especially when incorporating human feedback on representative data. For lack of a better term, I'll call this form of prompt optimization "Prompt Bootstrapping", since it iteratively refines a prompt via instruction tuning distilled from human feedback. Below is an overview of the process.
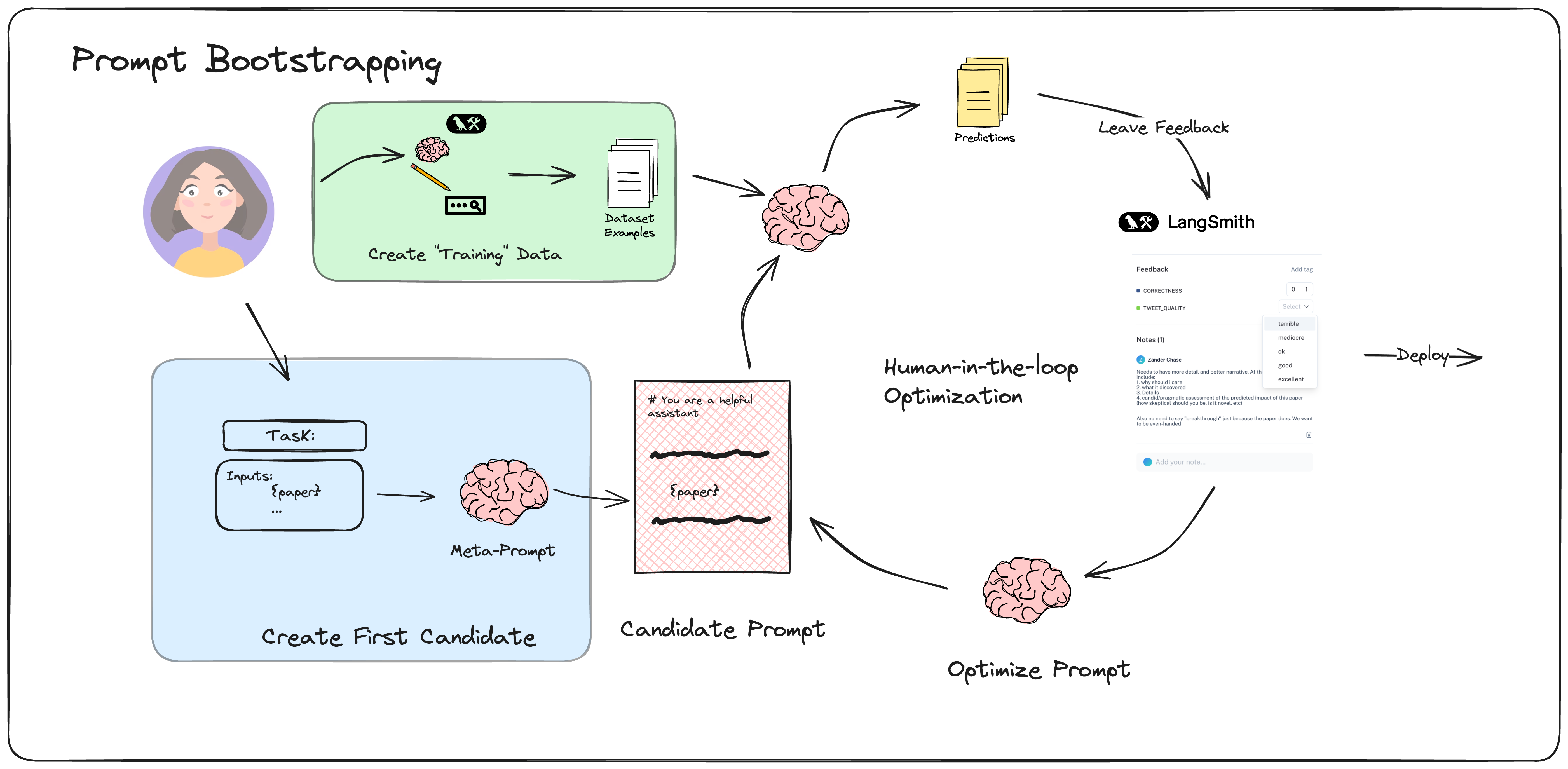
LangSmith makes this this whole flow very easy. Let's give it a whirl!
This example is based on @alexalbert's example Claude workflow.
%pip install -U langsmith langchain_anthropic langchain arxiv
import os
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY" # Update with your API key
# We are using Anthropic here as well
os.environ["ANTHROPIC_API_KEY"] = "YOUR API KEY"
from langsmith import Client
client = Client()
1. Pick a task
Let's say I want to write a tweet generator about academic papers, one that is catchy but not laden with too many buzzwords or impersonal. Let's see if we can "optimize" a prompt without having to engineer it ourselves.
We will use the meta-prompt (wfh/metaprompt) from the Hub to generate our first prompt candidate to solve this task.
from langchain import hub
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
task = (
"Generate a tweet to market an academic paper or open source project. It should be"
" well crafted but avoid gimicks or over-reliance on buzzwords."
)
# See: https://smith.langchain.com/hub/wfh/metaprompt
prompt = hub.pull("wfh/metaprompt")
llm = ChatAnthropic(model="claude-3-opus-20240229")
def get_instructions(gen: str):
return gen.split("<Instructions>")[1].split("</Instructions>")[0]
meta_prompter = prompt | llm | StrOutputParser() | get_instructions
recommended_prompt = meta_prompter.invoke(
{
"task": task,
"input_variables": """
{paper}
""",
}
)
print(recommended_prompt)
Here is the text of the academic paper or open source project to craft a marketing tweet for:
<paper> {paper} </paper>
Please follow these steps to generate the tweet:
-
Carefully read through the paper/project description. In 1-2 sentences, summarize the key point, main contribution or central finding of the work. Write this summary inside <key_point> tags.
-
Next, think about why this work matters. How is it significant to the field? What are the key implications or potential applications? Describe the importance concisely in 1-2 sentences inside <significance> tags.
-
Review the paper/project again and pick out 1-2 interesting statistics, impactful quotes, or illustrative examples that help convey the key ideas. Include these inside <highlight> tags.
-
Consider relevant hashtags to include that are topical to the subject area (e.g. #MachineLearning, #ClimateChange, #Genomics). Aim for 1-3 hashtags. Also consider any Twitter handles to @mention, such as the authors, lab/organization, or publisher. Include hashtags and mentions inside <hashtags> tags.
-
Now, craft the full tweet using the key point, significance, highlights, and hashtags you noted above. Aim for around 280 characters or less. Ensure the writing is clear, concise, and avoids gimmicky marketing language or an over-reliance on buzzwords. Focus on accurately and compellingly conveying the substance of the work.
Write the final generated tweet inside <tweet> tags.
OK so it's a fine-not-great prompt. Let's see how it does!
2. Dataset
For some tasks you can generate them yourselves. For our notebook, we have created a 10-datapoint dataset of some scraped ArXiv papers.
from itertools import islice
from langchain_community.utilities.arxiv import ArxivAPIWrapper
wrapper = ArxivAPIWrapper(doc_content_chars_max=200_000)
docs = list(islice(wrapper.lazy_load("Self-Replicating Language model Agents"), 10))
ds_name = "Tweet Generator"
ds = client.create_dataset(dataset_name=ds_name)
client.create_examples(
inputs=[{"paper": doc.page_content} for doc in docs], dataset_id=ds.id
)
3. Predict
We will refrain from defining metrics for now (it's quite subjective). Instead we will run the first version of the generator against the dataset and manually review + provide feedback on the results.
from langchain_core.prompts import PromptTemplate
def parse_tweet(response: str):
try:
return response.split("<tweet>")[1].split("</tweet>")[0].strip()
except:
return response.strip()
def create_tweet_generator(prompt_str: str):
prompt = PromptTemplate.from_template(prompt_str)
return prompt | llm | StrOutputParser() | parse_tweet
tweet_generator = create_tweet_generator(recommended_prompt)
# Example
prediction = tweet_generator.invoke({"paper": docs[0].page_content})
print(prediction)
res = client.run_on_dataset(
dataset_name=ds_name,
llm_or_chain_factory=tweet_generator,
)
View the evaluation results for project 'ample-price-67' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/096f2d40-c661-404f-8cb1-a384619cc262/compare?selectedSessions=962fc9fc-4f7d-4ccb-acd3-667c37763c47
View all tests for Dataset Tweet Generator 2 at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/096f2d40-c661-404f-8cb1-a384619cc262 [------------------------------------------------->] 10/10
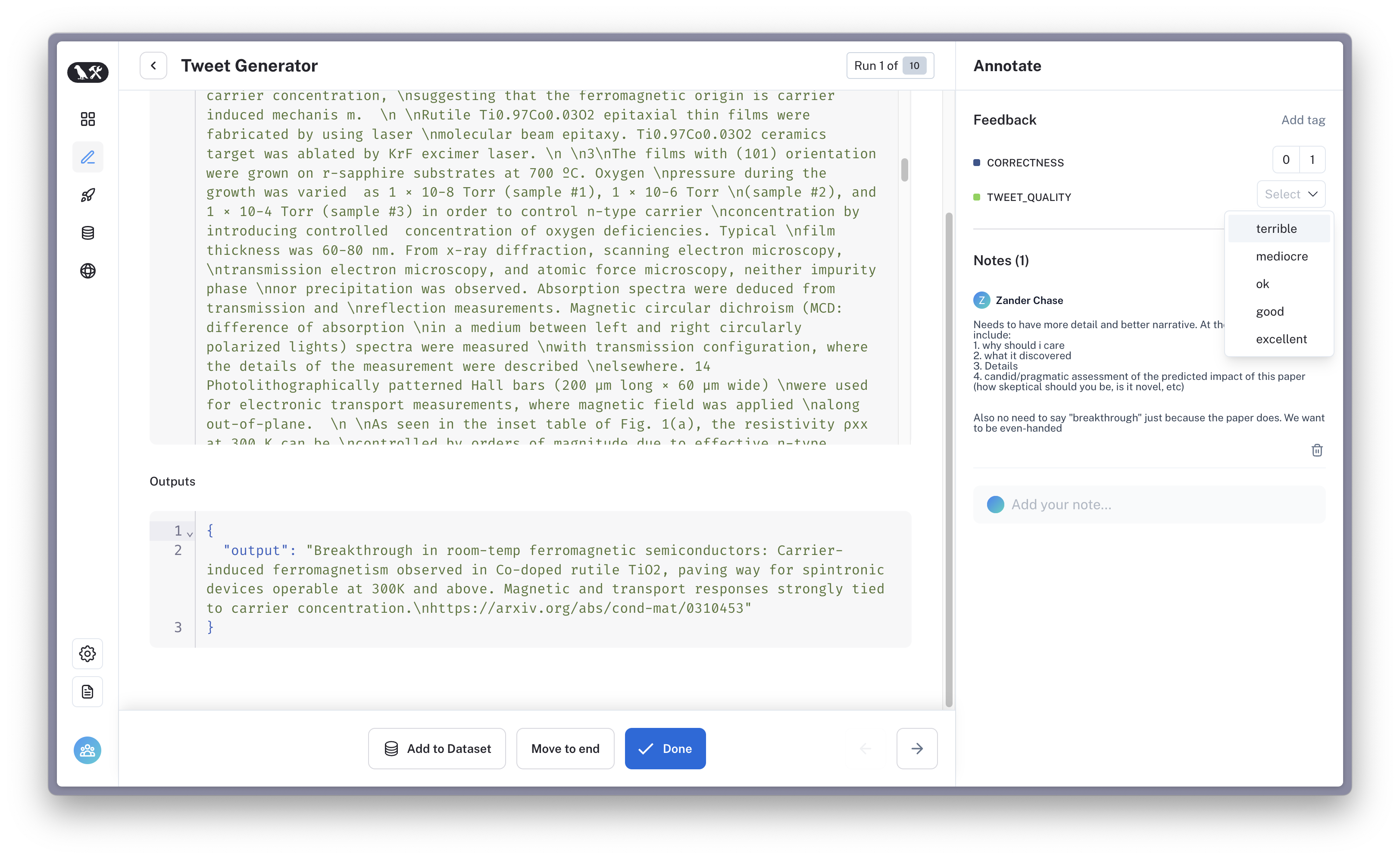
4. Label
Now, we will use an annotation queue to score + add notes to the results. We will use this to iterate on our prompt!
For this notebook, I will be logging two types of feedback:
note- freeform comments on the runs
tweet_quality - a 0-4 score of the generated tweet based on my subjective preferences
q = client.create_annotation_queue(name="Tweet Generator")
client.add_runs_to_annotation_queue(
q.id,
run_ids=[
r.id
for r in client.list_runs(project_name=res["project_name"], execution_order=1)
],
)
Now, go through the runs to label them. Return to this notebook when you are finished.
4. Update
With the human feedback in place, let's update the prompt and try again.
from collections import defaultdict
def format_feedback(single_feedback, max_score=4):
if single_feedback.score is None:
score = ""
else:
score = f"\nScore:[{single_feedback.score}/{max_score}]"
comment = f"\n{single_feedback.comment}".strip()
return f"""<feedback key={single_feedback.key}>{score}{comment}
</feedback>"""
def format_run_with_feedback(run, feedback):
all_feedback = "\n".join([format_feedback(f) for f in feedback])
return f"""<example>
<tweet>
{run.outputs["output"]}
</tweet>
<annotations>
{all_feedback}
</annotations>
</example>"""
def get_formatted_feedback(project_name: str):
traces = list(client.list_runs(project_name=project_name, execution_order=1))
feedbacks = defaultdict(list)
for f in client.list_feedback(run_ids=[r.id for r in traces]):
feedbacks[f.run_id].append(f)
return [
format_run_with_feedback(r, feedbacks[r.id])
for r in traces
if r.id in feedbacks
]
formatted_feedback = get_formatted_feedback(res["project_name"])
LLMs are especially good at 2 things:
- Generating grammatical text
- Summarization
Now that we've left a mixture of scores and free-form comments, we can use an "optimizer prompt" (wfh/optimizerprompt) to incorporate the feedback into an updated prompt.
# See: https://smith.langchain.com/hub/wfh/optimizerprompt
optimizer_prompt = hub.pull("wfh/optimizerprompt")
def extract_new_prompt(gen: str):
return gen.split("<improved_prompt>")[1].split("</improved_prompt>")[0].strip()
optimizer = optimizer_prompt | llm | StrOutputParser() | extract_new_prompt
current_prompt = recommended_prompt
new_prompt = optimizer.invoke(
{
"current_prompt": current_prompt,
"annotated_predictions": "\n\n".join(formatted_feedback).strip(),
}
)
print("Original Prompt\n\n" + current_prompt)
print("*" * 80 + "\nNew Prompt\n\n" + new_prompt)
Original Prompt
Here is the text of the academic paper or open source project to craft a marketing tweet for:
<paper> {paper} </paper>
Please follow these steps to generate the tweet:
-
Carefully read through the paper/project description. In 1-2 sentences, summarize the key point, main contribution or central finding of the work. Write this summary inside <key_point> tags.
-
Next, think about why this work matters. How is it significant to the field? What are the key implications or potential applications? Describe the importance concisely in 1-2 sentences inside <significance> tags.
-
Review the paper/project again and pick out 1-2 interesting statistics, impactful quotes, or illustrative examples that help convey the key ideas. Include these inside <highlight> tags.
-
Consider relevant hashtags to include that are topical to the subject area (e.g. #MachineLearning, #ClimateChange, #Genomics). Aim for 1-3 hashtags. Also consider any Twitter handles to @mention, such as the authors, lab/organization, or publisher. Include hashtags and mentions inside <hashtags> tags.
-
Now, craft the full tweet using the key point, significance, highlights, and hashtags you noted above. Aim for around 280 characters or less. Ensure the writing is clear, concise, and avoids gimmicky marketing language or an over-reliance on buzzwords. Focus on accurately and compellingly conveying the substance of the work.
Write the final generated tweet inside <tweet> tags.
New Prompt
Here is the text of the academic paper or open source project to craft a marketing tweet for:
<paper> {paper} </paper>
Please follow these steps to generate an engaging, informative tweet:
-
Carefully read through the paper/project description. Identify the central thesis, key innovations, and main takeaways of the work.
-
Craft a compelling opening line to grab the reader's attention and make them want to learn more. Avoid generic phrases like "New study" or "Introducing X". Instead, lead with an intriguing question, provocative statement, or interesting statistic related to the work.
-
Briefly summarize the key details of what makes this work novel - whether that's the methods used, experiments run, results achieved etc. Go beyond just stating the topic and convey specifically what about the approach or findings is unique and noteworthy.
-
Explain the significance of the work and implications of the results. Why does this matter? How does it advance the field or open up new possibilities? Clearly convey the "so what" to the reader.
-
If relevant, include 1-2 key statistics, quotes or examples to illustrate the main ideas. Choose ones that are especially attention-grabbing or memorable.
-
If appropiate, include 1-2 highly relevant hashtags (e.g. #MachineLearning, #ClimateChange) and/or @mentions of the authors, lab, or publisher. Only include if they are directly topical and useful for categorizing the content or highlighting sources. Do not force hashtags/mentions if they feel unnatural.
-
Aim for a total tweet length of around 200-280 characters. Format the tweet in 2-3 short paragraphs for easy readability and logical flow.
-
Close with a direct, concise assessment of how impactful or potentially paradigm-shifting you believe this work to be based on your analysis. Avoid exaggeration or hype, but candidly convey if you think this is an especially groundbreaking or important paper.
Write the final generated tweet inside <tweet> tags. Remember to focus on really grabbing the reader's attention, clearly conveying the key details and significance, and offering an authentic assessment of the importance of the work. Let your enthusiasm shine through while sticking to the facts.
5. Repeat!
Now that we have an "upgraded" prompt, we can test it out again and repeat until we are satisfied with the result.
If you find the prompt isn't converging to something you want, you can manually update the prompt (you are the optimizer in this case) and/or be more explicit in your free-form note feedback.
tweet_generator = create_tweet_generator(new_prompt)
updated_results = client.run_on_dataset(
dataset_name=ds_name,
llm_or_chain_factory=tweet_generator,
)
View the evaluation results for project 'drab-crate-45' at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/096f2d40-c661-404f-8cb1-a384619cc262/compare?selectedSessions=8b1bde1d-47d7-4085-92c8-274193cd1855
View all tests for Dataset Tweet Generator 2 at: https://smith.langchain.com/o/ebbaf2eb-769b-4505-aca2-d11de10372a4/datasets/096f2d40-c661-404f-8cb1-a384619cc262 [------------------------------------------------->] 10/10
client.add_runs_to_annotation_queue(
q.id,
run_ids=[
r.id
for r in client.list_runs(
project_name=updated_results["project_name"], execution_order=1
)
],
)
Then review/provide feedback/repeat.
Once you've provided feedback, you can continue here:
formatted_feedback = get_formatted_feedback(updated_results["project_name"])
# Swap them out
current_prompt = new_prompt
new_prompt = optimizer.invoke(
{
"current_prompt": current_prompt,
"annotated_predictions": "\n\n".join(formatted_feedback).strip(),
}
)
print("Previous Prompt\n\n" + current_prompt)
print("*" * 80 + "\nNew Prompt\n\n" + new_prompt)
Previous Prompt
Your task is to write an engaging tweet to market the following academic paper or open source project:
<paper> {paper} </paper>
Here are the key elements to include in your tweet:
-
Concisely summarize the most important new findings from the paper. Focus on the key advances rather than the minutiae of the methodology.
-
Explain why the findings are important or how they could lead to new applications. Avoid overhyped terms like "breakthrough" and focus on clear, grounded explanations using concrete examples where possible.
-
Briefly define any essential technical jargon that appears in your summary (e.g. what are "spintronic devices"?). Aim to make the significance of the work accessible to a broad audience.
-
Credit the authors and/or their institutions, and include a link to the paper/project.
Feel free to use more than 280 characters to achieve a good balance of being punchy and interesting while also including key context and explanations. But don't let it become too dense or long-winded.
Here's an example of the kind of tone and content to aim for:
<tweet> New record: 29.5% efficiency solar cells achieved by stacking perovskite-silicon tandem cell. That's 4% higher than standard Si cells! Promising path to ultra-high efficiency at lower costs. Perovskites are semiconductors that can be "tuned" to absorb different light colors. https://doi.org/10.1038/s41586-023-46736-2 By M. Jeong et al. @SomaiyaVidyavihar </tweet>
Don't copy this example directly, but use it as a guide for the style and level of detail to try to emulate for the paper provided.
Write out the full text of your proposed tweet inside <tweet> tags.
New Prompt
Your task is to write an engaging tweet to market the following academic paper or open source project:
<paper> {paper} </paper>
Structure your tweet in the following way:
-
Identify the key problem or opportunity that the new work addresses. This should be the attention-grabbing "hook" that leads your tweet.
-
Concisely explain what the researchers did and how they did it. Focus on the most important and novel aspects of their work. Avoid getting bogged down in methodological details.
-
Briefly explain any essential technical concepts to make the significance of the work more accessible to a broad audience. Use plain language rather than jargon where possible.
-
Discuss the potential impact and applications of the work moving forward. Be specific and grounded rather than making hyperbolic claims. Explain how this work could lead to advances in the field.
-
Provide a link to the paper or project, and credit the authors and their institutions.
Aim for a total tweet length of 250-350 characters. Focus on being punchy and compelling while still including key details and context.
Here's an example of a strong tweet following this structure:
<tweet> Room-temp ferromagnetic semiconductor could revolutionize spintronics and quantum computing. Zhang & Sui grew graphene on nickel, opening a bandgap & splitting electron spins. Harnesses graphene's unique properties in new ways for nonvolatile memory & more. https://doi.org/10.1038/s41563-023-01587-y @BeijingNormalU @TsinghuaUni </tweet>
Use this as a guide for the style and content to aim for. Write your tweet inside <tweet> tags.
Conclusion
Congrats! You've "optimized" a prompt on a subjective task using human feedback and an automatic prompt engineer flow. LangSmith makes it easy to score and improve LLM systems even when it is hard to craft a hard metric.
You can push the optimized version of your prompt to the hub (here and in future iterations) to version each change.
hub.push("wfh/academic-tweet-generator", PromptTemplate.from_template(new_prompt))
'https://smith.langchain.com/hub/wfh/academic-tweet-generator/03670db0'
Extensions:
We haven't optimized the meta-prompts above - feel free to make them your own by forking and updating them! Some easy extensions you could try out include:
- Including the full history of previous prompts and annotations (or most recent N prompts with feedback) in the "optimizer prompt" step. This may help it better converge (especially if you're using a small dataset)
- Updating the optimizer prompt to encourage usage of few-shot examples, or to encourage other prompting tricks.
- Incorporating an LLM judge by including the annotation few-shot examples and instructing it to critique the generated outputs: this could help speed-up the human annotation process.
- Generating and including a validation set (to avoid over-fitting this training dataset)