Real-time Automated Feedback
![]()
![]()
This tutorial shows how to attach a reference-free evaluator as a callback to your chain to automatically generate feedback for each trace. LangSmith can use this information to help you monitor the quality of your deployment.
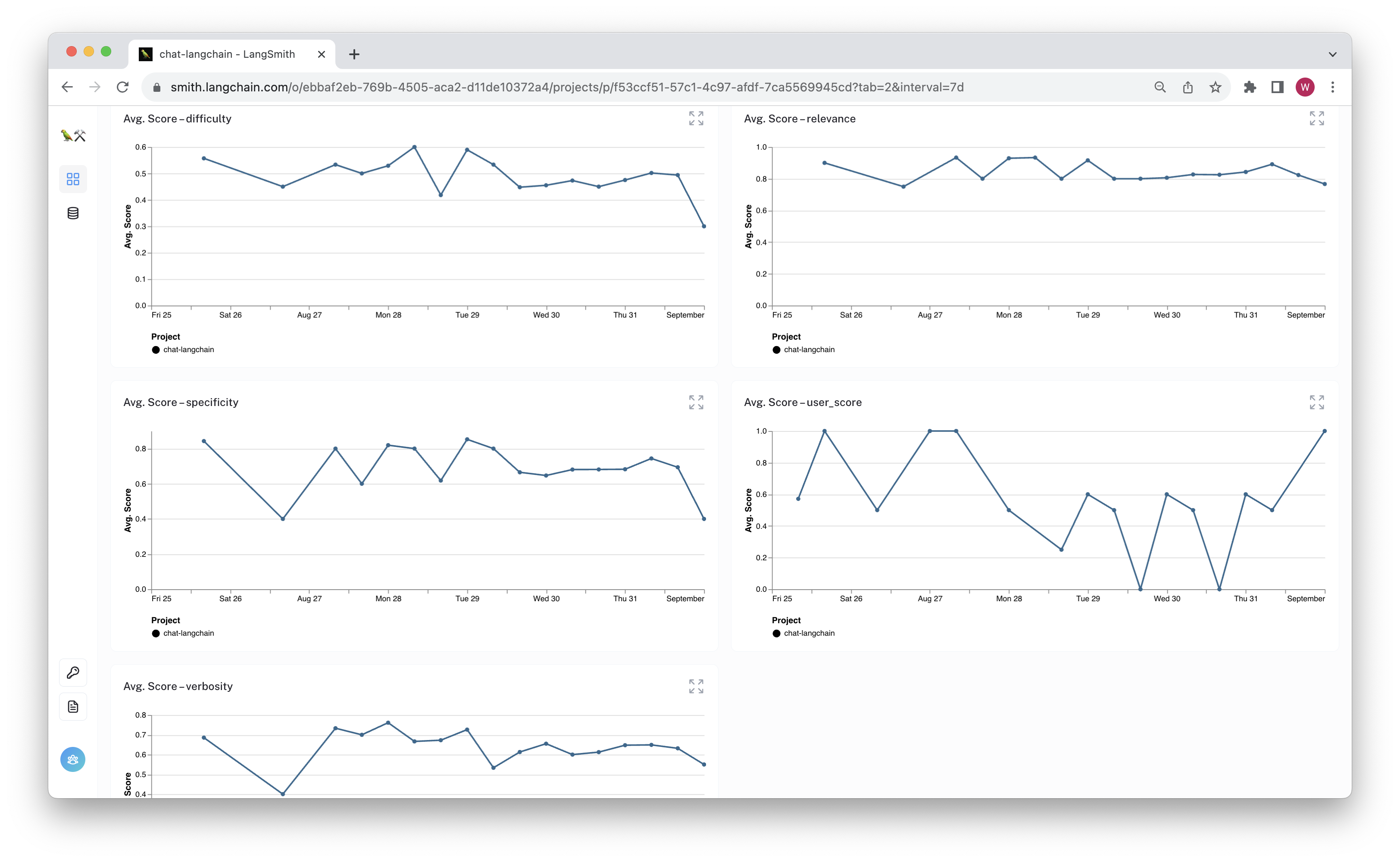
If the metrics reveal issues, you can isolate problematic runs for debugging or fine-tuning.
Steps:
-
Define Feedback Logic: Create a RunEvaluator to calculate the feedback metrics. We will use LangChain's "CriteriaEvaluator" as an example.
-
Include in callbacks: Using the EvaluatorCallbackHandler, we can make sure the evaluators are applied any time a trace is completed.
We'll be using LangSmith, so make sure you have the necessary API keys.
%pip install -U langchain openai --quiet
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY" # Update with your API key
os.environ["LANGCHAIN_PROJECT"] = "YOUR PROJECT NAME" # Change to your project name
Once you've decided the runs you want to evaluate, it's time to define the feedback pipeline.
1. Define feedback logic
All feedback needs a key and should have a (nullable) numeric score. You can apply any algorithm to generate these scores, but you'll want to choose the one that makes the most sense for your use case.
The following example selects the "input" and "output" keys of the trace and returns 1 if the algorithm believes the response to be "helpful", 0 otherwise.
LangChain has a number of reference-free evaluators you can use off-the-shelf or configure to your needs. You can apply these directly to your runs to log the evaluation results as feedback. For more information on available LangChain evaluators, check out the open source documentation.
from typing import Optional
from langchain.evaluation import load_evaluator
from langsmith.evaluation import RunEvaluator, EvaluationResult
from langsmith.schemas import Run, Example
class HelpfulnessEvaluator(RunEvaluator):
def __init__(self):
self.evaluator = load_evaluator(
"score_string", criteria="helpfulness", normalize_by=10
)
def evaluate_run(
self, run: Run, example: Optional[Example] = None
) -> EvaluationResult:
if (
not run.inputs
or not run.inputs.get("input")
or not run.outputs
or not run.outputs.get("output")
):
return EvaluationResult(key="helpfulness", score=None)
result = self.evaluator.evaluate_strings(
input=run.inputs["input"], prediction=run.outputs["output"]
)
return EvaluationResult(
**{"key": "helpfulness", "comment": result.get("reasoning"), **result}
)
Here, we are using the collect_runs callback handler to easily fetch the run ID from the evaluation run. By adding it to the evaluator_info, the feedback will retain a link from the evaluated run to the source run so you can see why the tag was generated. Below, we will log feedback to all the traces in our project.
2. Include in callbacks
We can use the EvaluatorCallbackHandler to automatically call the evaluator in a separate thread any time a trace is complete.
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
chain = (
ChatPromptTemplate.from_messages([("user", "{input}")])
| ChatOpenAI()
| StrOutputParser()
)
Then create the callback. This callback runs the evaluators in a separate thread.
from langchain.callbacks.tracers.evaluation import EvaluatorCallbackHandler
evaluator = HelpfulnessEvaluator()
feedback_callback = EvaluatorCallbackHandler(evaluators=[evaluator])
queries = [
"Where is Antioch?",
"What was the US's inflation rate in 2018?",
"Who were the stars in the show Friends?",
"How much wood could a woodchuck chuck if a woodchuck could chuck wood?",
"Why is the sky blue?",
"When is Rosh hashanah in 2023?",
]
for query in queries:
chain.invoke({"input": query}, {"callbacks": [feedback_callback]})
Check out the target project to see the feedback appear as the runs are evaluated.
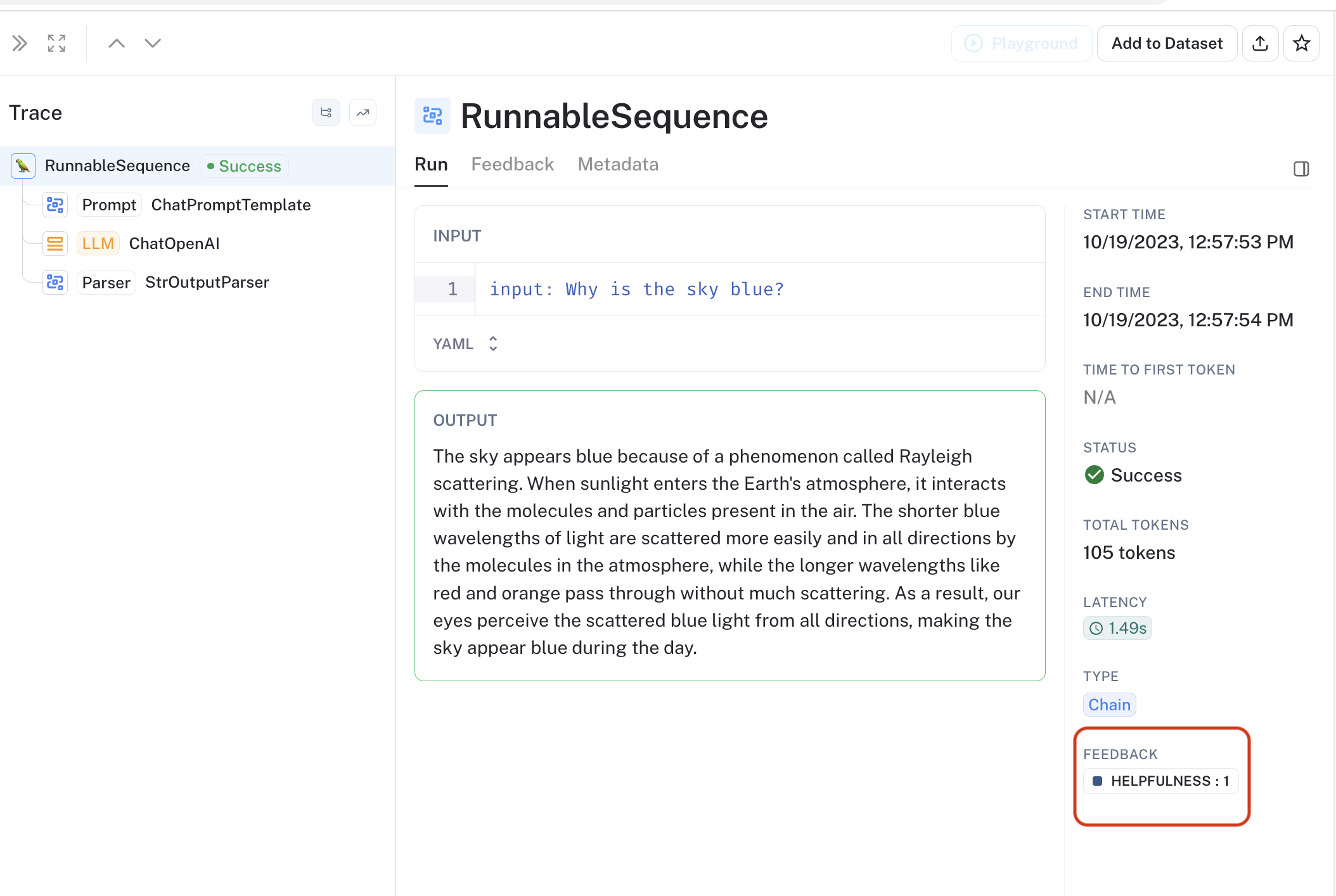
Conclusion
Congrats! You've configured an evaluator to run any time your chain is called. This will generate relevant metrics you can use to track your deployment.