Creating an Automated Feedback Pipeline with LangSmith
![]()
![]()
Manually analyzing text processed by your language model is useful, but not scalable. Automated metrics offer a solution. By adding these metrics to your LangSmith projects, you can track advanced metrics on your LLM's performance and user inputs directly from the dashboard.
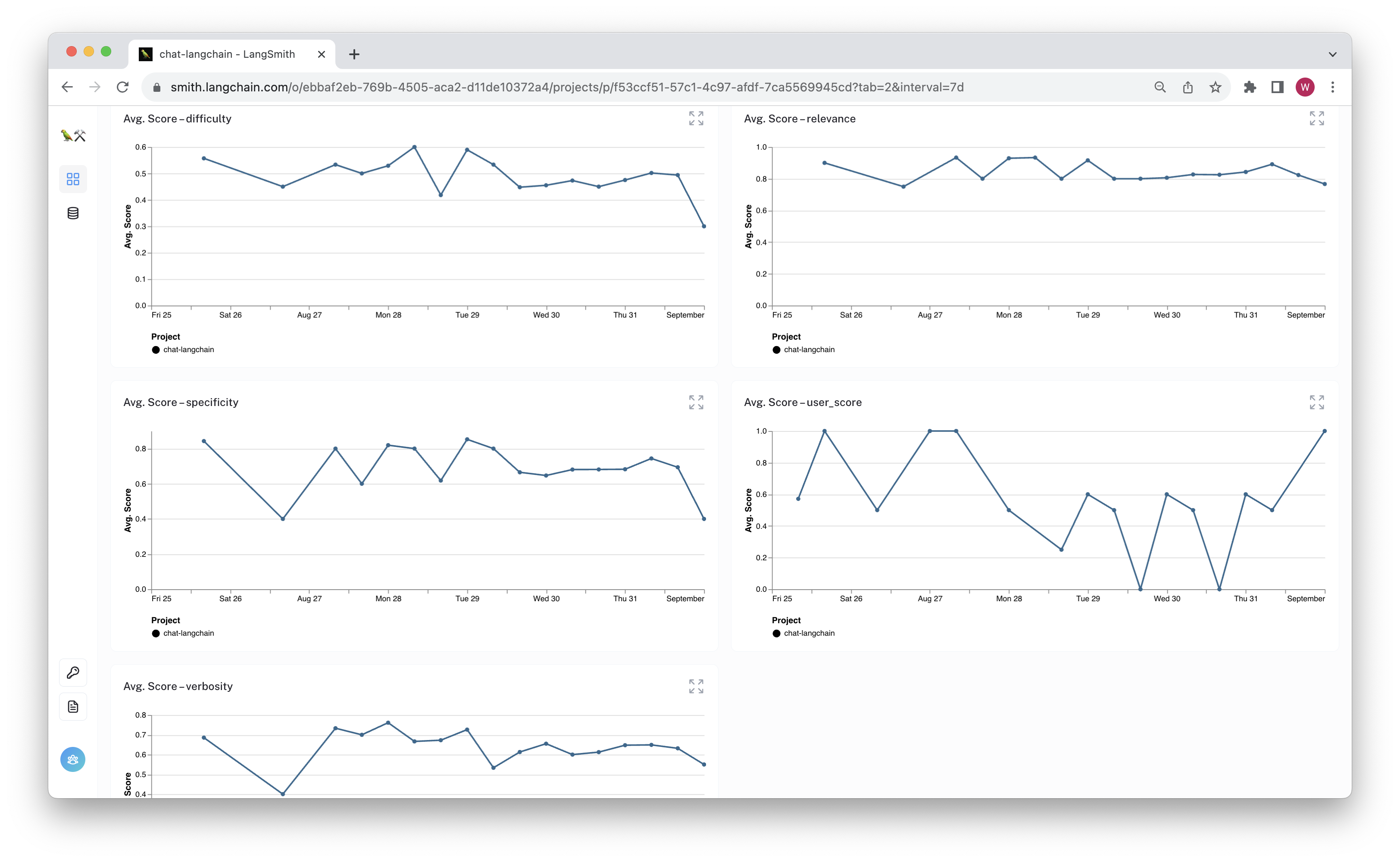
If the metrics reveal issues, you can isolate problematic runs for debugging or fine-tuning. This tutorial shows you how to set up an automated feedback pipeline for your language models.
Steps:
- Filter Runs: First, identify the runs you want to evaluate. For details, refer to the Run Filtering Documentation.
- Define Feedback Logic: Create a chain or function to calculate the feedback metrics.
- Send Feedback to LangSmith:
- Use the
client.create_feedbackmethod to send metrics. - Alternatively, use
client.evaluate_run, which both evaluates and logs metrics for you.
- Use the
We'll be using LangSmith and the hub APIs, so make sure you have the necessary API keys.
import os
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
# Update with your API key
os.environ["LANGCHAIN_API_KEY"] = "YOUR API KEY"
# Update with your API URL if using a hosted instance of Langsmith.
os.environ["LANGCHAIN_HUB_API_URL"] = "https://api.hub.langchain.com"
# Update with your Hub API key
os.environ["LANGCHAIN_HUB_API_KEY"] = "YOUR API KEY"
project_name = "YOUR PROJECT NAME" # Change to your project name
We will create some example runs in this project to get us off on a shared footing.
from langsmith import Client
from datetime import datetime
client = Client()
example_data = [
("Who trained Llama-v2?", "I'm sorry, but I don't have that information."),
(
"When did langchain first announce the hub?",
"LangChain first announced the LangChain Hub on September 5, 2023.",
),
(
"What's LangSmith?",
"LangSmith is a platform developed by LangChain for building production-grade LLM (Language Model) applications. It allows you to debug, test, evaluate, and monitor chains and intelligent agents built on any LLM framework. LangSmith seamlessly integrates with LangChain's open-source framework called LangChain, which is widely used for building applications with LLMs.\n\nLangSmith provides full visibility into model inputs and outputs at every step in the chain of events, making it easier to debug and analyze the behavior of LLM applications. It has been tested with early design partners and on internal workflows, and it has been found to help teams in various ways.\n\nYou can find more information about LangSmith on the official LangSmith documentation [here](https://docs.smith.langchain.com/). Additionally, you can read about the announcement of LangSmith as a unified platform for debugging and testing LLM applications [here](https://blog.langchain.dev/announcing-langsmith/).",
),
(
"What is the langsmith cookbook?",
"I'm sorry, but I couldn't find any information about the \"Langsmith Cookbook\". It's possible that it may not be a well-known cookbook or it may not exist. Could you provide more context or clarify the name?",
),
(
"What is LangChain?",
"I'm sorry, but I couldn't find any information about \"LangChain\". Could you please provide more context or clarify your question?",
),
("When was Llama-v2 released?", "Llama-v2 was released on July 18, 2023."),
]
for input_, output_ in example_data:
client.create_run(
name="ExampleRun",
run_type="chain",
inputs={"input": input_},
outputs={"output": output_},
project_name=project_name,
end_time=datetime.utcnow(),
)
1. Select Runs
In this example, we will be adding model-based feedback to the run traces within a single project. To find your project name or ID, you can go to the Projects page for your organization and then call the list_runs() method on the LangSmith client.
runs = client.list_runs(project_name=project_name)
If your project is capturing logs from a deployed chain or agent, you'll likely want to filter based on time so you can run the feedback pipeline on a schedul. The query below filters for runs since midnight, last-night UTC. You can also filter for other things, like runs without errors, runs with specific tags, etc. For more information on doing so, check out the Run Filtering guide to learn more.
midnight = datetime.utcnow().replace(hour=0, minute=0, second=0, microsecond=0)
runs = list(
client.list_runs(
project_name=project_name, execution_order=1, start_time=midnight, errors=False
)
)
Once you've decided the runs you want to evaluate, it's time to define the feedback pipeline.
2. Define Feedback Algorithm
All feedback needs a key and should have a (nullable) numeric score. You can apply any algorithm to generate these scores, but you'll want to choose the one that makes the most sense for your use case.
The following examples run on the "input" and "output" keys of runs. If your runs use different keys, you may have to update.
Example A: Simple Text Statistics
We will start out by adding some simple text statistics on the input text as feedback. We use this to illustrate that you can use any simple or custom algorithm to generate scores.
Scores can be null, boolean, integesr, or float values.
Note: We are measuring the 'input' key in this example, which is used by LangChain's AgentExecutor class. You will want to confirm the key(s) you want to measure within the run's inputs or outputs dictionaries when applying this example. Common run types (like 'chat' runs) have nested dictionaries.
%pip install textstat --quiet
Note: you may need to restart the kernel to use updated packages.
import textstat
from langsmith.schemas import Run, Example
from langchain.schema.runnable import RunnableLambda
def compute_stats(run: Run) -> None:
# Note: your chain's runs may have different keys.
# Be sure to select the right field(s) to measure!
if "input" not in run.inputs:
return
if run.feedback_stats and "smog_index" in run.feedback_stats:
# If we are running this pipeline multiple times
return
text = run.inputs["input"]
try:
fns = [
"flesch_reading_ease",
"flesch_kincaid_grade",
"smog_index",
"coleman_liau_index",
"automated_readability_index",
]
metrics = {fn: getattr(textstat, fn)(text) for fn in fns}
for key, value in metrics.items():
client.create_feedback(
run.id,
key=key,
score=value, # The numeric score is used in the monitoring charts
feedback_source_type="model",
)
except:
pass
# Concurrently log feedback. You could also run this in a 'for' loop
# And not use any langchain code
_ = RunnableLambda(compute_stats).batch(
runs,
{"max_concurrency": 10},
return_exceptions=True,
)
Example B: AI-assisted feedback
Text statistics are simple to generate but often not very informative. Let's make an example that scores each run's input using an LLM. This method lets you score runs based on targeted axes relevant to your application. You could apply this technique to select metrics as proxies for quality or to help curate data to fine-tune an LLM.
In the example below, we will instruct an LLM to score user input queries along a number of simple axes. We will be using this prompt to drive the chain.
from langchain import hub
prompt = hub.pull(
"wfh/automated-feedback-example", api_url="https://api.hub.langchain.com"
)
from langchain.chat_models import ChatOpenAI
from langchain.callbacks import collect_runs
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
chain = (
prompt
| ChatOpenAI(model="gpt-3.5-turbo", temperature=1).bind(
functions=[
{
"name": "submit_scores",
"description": "Submit the graded scores for a user question and bot response.",
"parameters": {
"type": "object",
"properties": {
"relevance": {
"type": "integer",
"minimum": 0,
"maximum": 5,
"description": "Score indicating the relevance of the question to LangChain/LangSmith.",
},
"difficulty": {
"type": "integer",
"minimum": 0,
"maximum": 5,
"description": "Score indicating the complexity or difficulty of the question.",
},
"verbosity": {
"type": "integer",
"minimum": 0,
"maximum": 5,
"description": "Score indicating how verbose the question is.",
},
"specificity": {
"type": "integer",
"minimum": 0,
"maximum": 5,
"description": "Score indicating how specific the question is.",
},
},
"required": ["relevance", "difficulty", "verbosity", "specificity"],
},
}
]
)
| JsonOutputFunctionsParser()
)
def evaluate_run(run: Run) -> None:
try:
# Note: your chain's runs may have different keys.
# Be sure to select the right field(s) to measure!
if "input" not in run.inputs or not run.outputs or "output" not in run.outputs:
return
if run.feedback_stats and "specificity" in run.feedback_stats:
# We have already scored this run
# (if you're running this pipeline multiple times)
return
with collect_runs() as cb:
result = chain.invoke(
{
"question": run.inputs["input"][:3000], # lazy truncation
"prediction": run.outputs["output"][:3000],
},
)
for feedback_key, value in result.items():
score = int(value) / 5
client.create_feedback(
run.id,
key=feedback_key,
score=score,
source_run_id=cb.traced_runs[0].id,
feedback_source_type="model",
)
except Exception as e:
pass
wrapped_function = RunnableLambda(evaluate_run)
# Concurrently log feedback
_ = wrapped_function.batch(runs, {"max_concurrency": 10}, return_exceptions=True)
# Updating the aggregate stats is async, but after some time, the logged feedback stats
client.read_project(project_name=project_name).feedback_stats
{'smog_index': {'n': 6, 'avg': 0.0, 'mode': 0, 'is_all_model': True},
'coleman_liau_index': {'n': 6,
'avg': 7.825,
'mode': 3.43,
'is_all_model': True},
'flesch_reading_ease': {'n': 6,
'avg': 92.79666666666667,
'mode': 75.88,
'is_all_model': True},
'flesch_kincaid_grade': {'n': 6,
'avg': 1.3,
'mode': 2.9,
'is_all_model': True},
'automated_readability_index': {'n': 6,
'avg': 9.0,
'mode': 5.2,
'is_all_model': True}}
Example C: LangChain Evaluators
LangChain has a number of reference-free evaluators you can use off-the-shelf or configure to your needs. You can apply these directly to your runs to log the evaluation results as feedback. For more information on available LangChain evaluators, check out the open source documentation.
Below, we will demonstrate this by using the criteria evaluator, which instructs an LLM to check that the prediction against the described criteria. The criterion we specify will be "completeness".
from typing import Optional
from langchain import evaluation, callbacks
from langsmith import evaluation as ls_evaluation
class CompletenessEvaluator(ls_evaluation.RunEvaluator):
def __init__(self):
criteria_description = (
"Does the answer provide sufficient and complete information"
"to fully address all aspects of the question (Y)?"
" Or does it lack important details (N)?"
)
self.evaluator = evaluation.load_evaluator(
"criteria", criteria={"completeness": criteria_description}
)
def evaluate_run(
self, run: Run, example: Optional[Example] = None
) -> ls_evaluation.EvaluationResult:
if (
not run.inputs
or not run.inputs.get("input")
or not run.outputs
or not run.outputs.get("output")
):
return ls_evaluation.EvaluationResult(key="completeness", score=None)
question = run.inputs["input"]
prediction = run.outputs["output"]
with callbacks.collect_runs() as cb:
result = self.evaluator.evaluate_strings(
input=question, prediction=prediction
)
run_id = cb.traced_runs[0].id
return ls_evaluation.EvaluationResult(
key="completeness", evaluator_info={"__run": {"run_id": run_id}}, **result
)
Here, we are using the collect_runs callback handler to easily fetch the run ID from the evaluation run. By adding it to the evaluator_info, the feedback will retain a link from the evaluated run to the source run so you can see why the tag was generated. Below, we will log feedback to all the traces in our project.
evaluator = CompletenessEvaluator()
# We can run as a regular for loop
# for run in runs:
# client.evaluate_run(run, evaluator)
# Or concurrently log feedback
wrapped_function = RunnableLambda(lambda run: client.evaluate_run(run, evaluator))
_ = wrapped_function.batch(runs, {"max_concurrency": 10}, return_exceptions=True)
Check out the target project to see the feedback appear as the runs are evaluated.
Conclusion
Congrats! You've set up an algorithmic feedback script to apply to your traced runs. This can improve the quality of your monitoring metrics, help to curate data for fine-tuning datasets, and let you better explore the usage of your app.