Managing Datasets
In LangSmith
The easiest way to interact with datasets is directly in the LangSmith app. Here, you can create and edit datasets and example rows. Below are a few ways to interact with them.
From Existing Runs
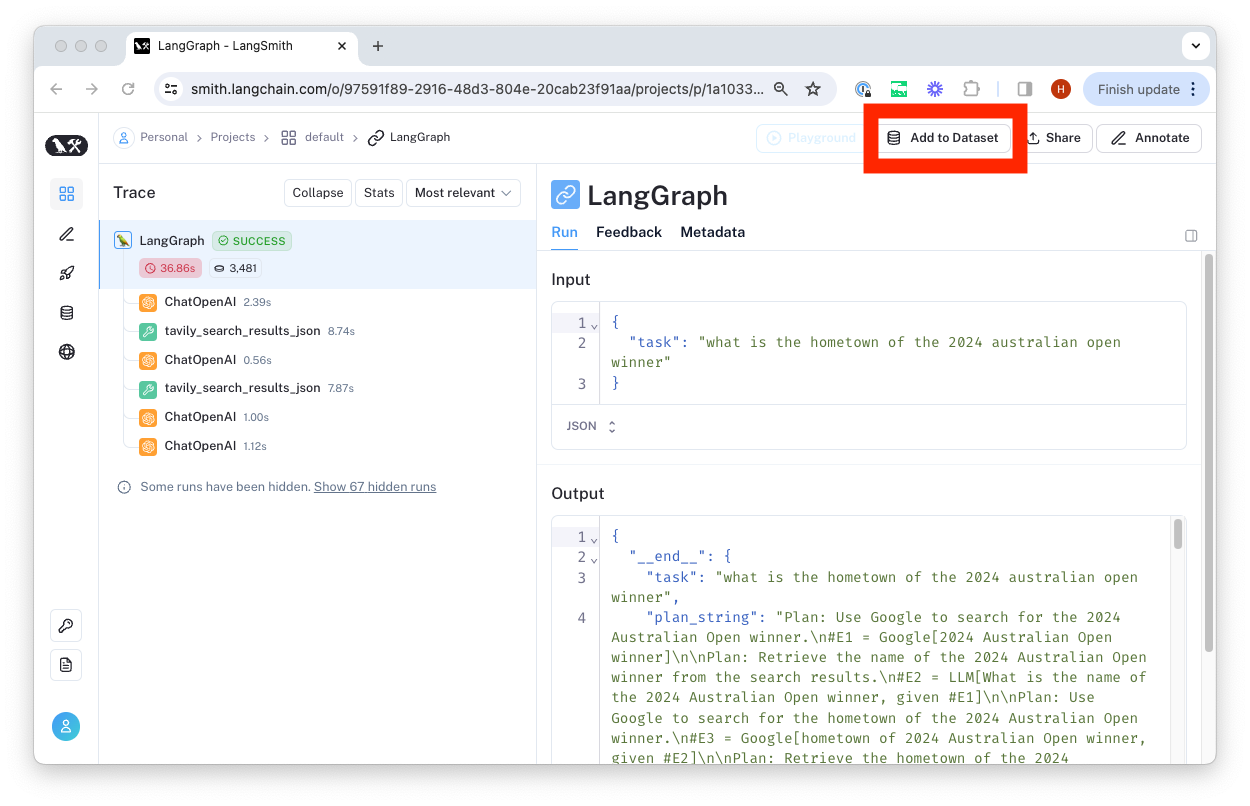
We typically construct datasets over time by collecting representative examples from debugging or other runs. To do this, we first filter the runs to find the ones we want to add to the dataset. Then, we create a dataset and add the runs as examples.
You can do this from any 'run' details page by clicking the 'Add to Dataset' button in the top right-hand corner.
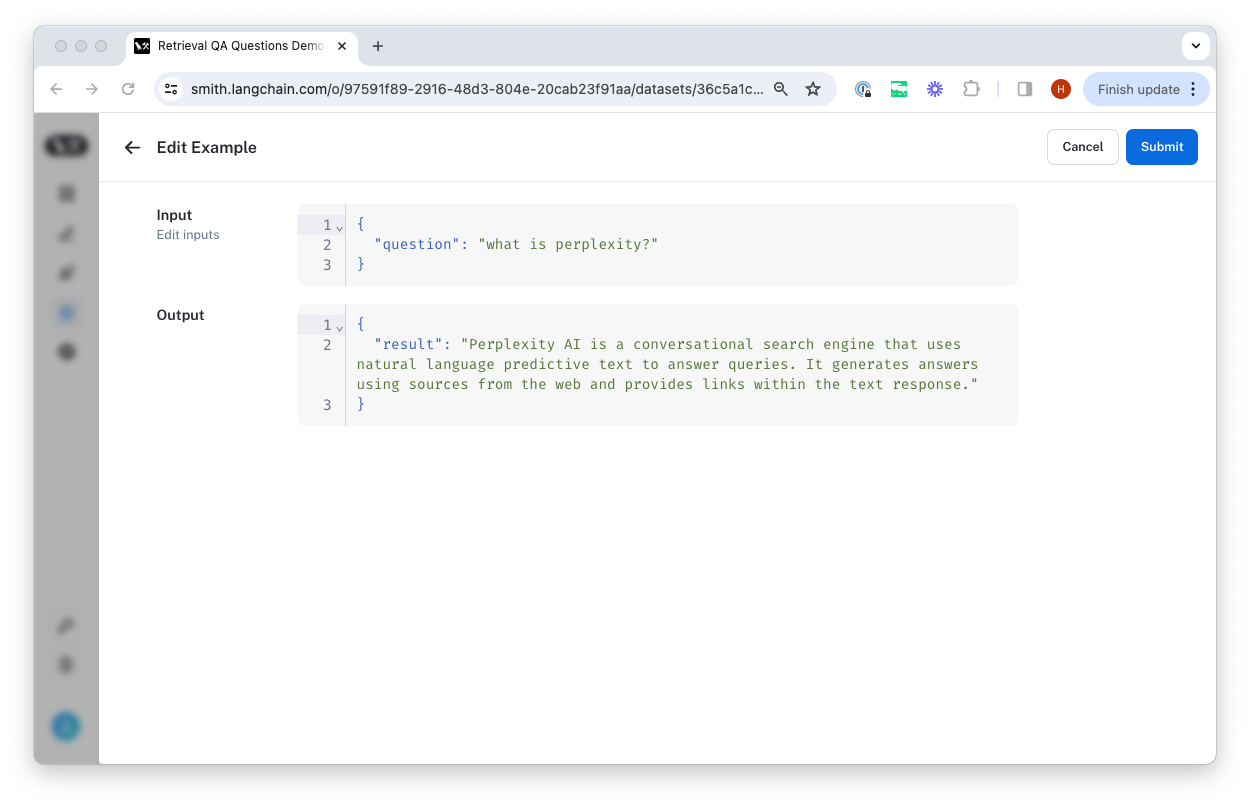
From there, we select the dataset to organize it in and update the ground truth output values if necessary.
Upload a CSV
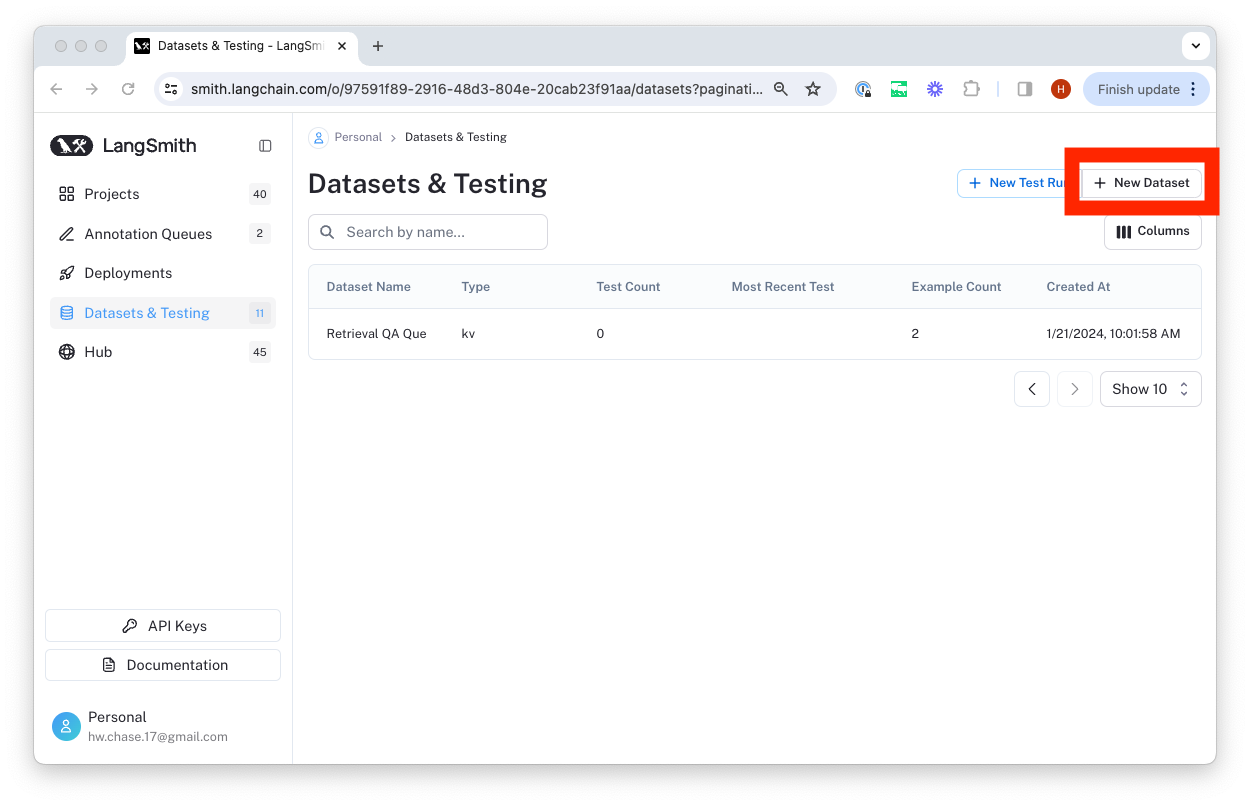
The easiest way to create a dataset from your own data is by clicking the 'upload a CSV dataset' button on the home page or in the top right-hand corner of the 'Datasets & Testing' page.
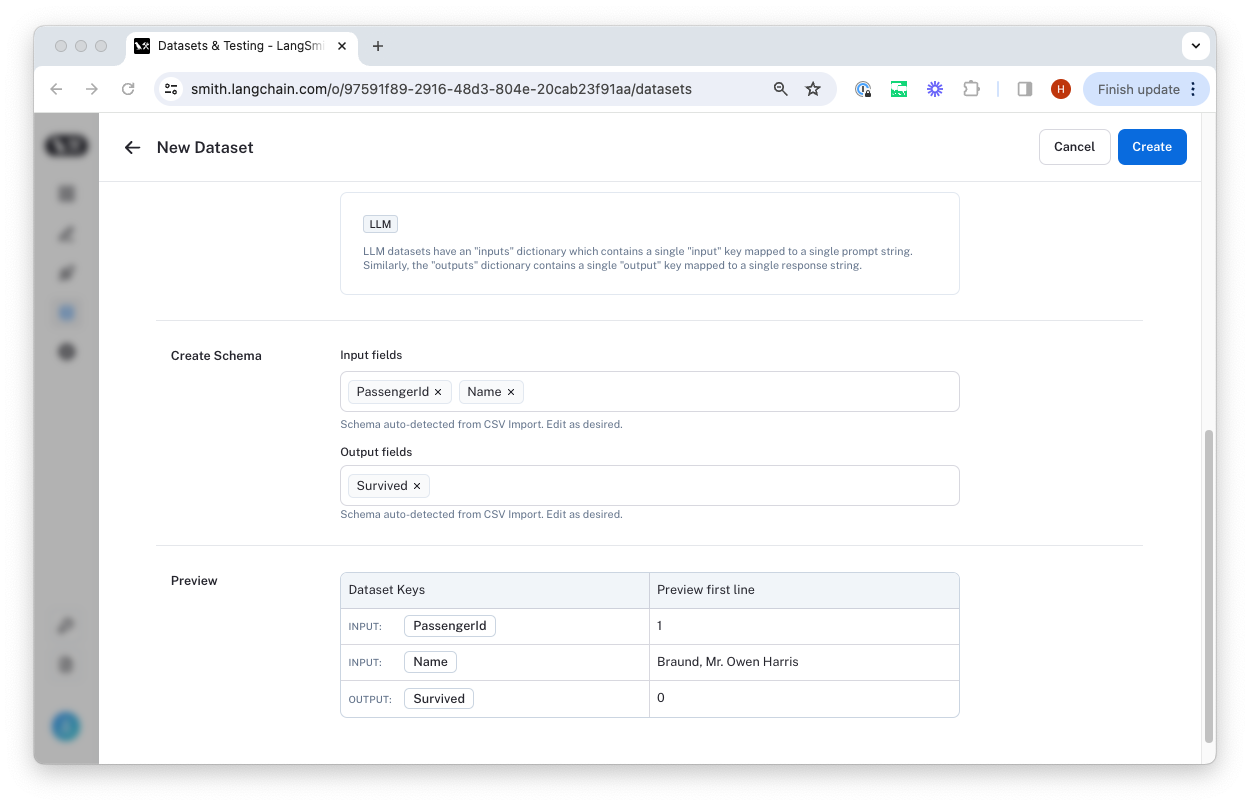
Select a name and description for the dataset, and then confirm that the inferred input and output columns are correct.
Exporting datasets to other formats
You can export your LangSmith dataset to CSV or OpenAI evals format directly from the web application.
To do so, click "Export Dataset" from the homepage. To do so, select a dataset, click on "Examples", and then click the "Export Dataset" button at the top of the examples table.
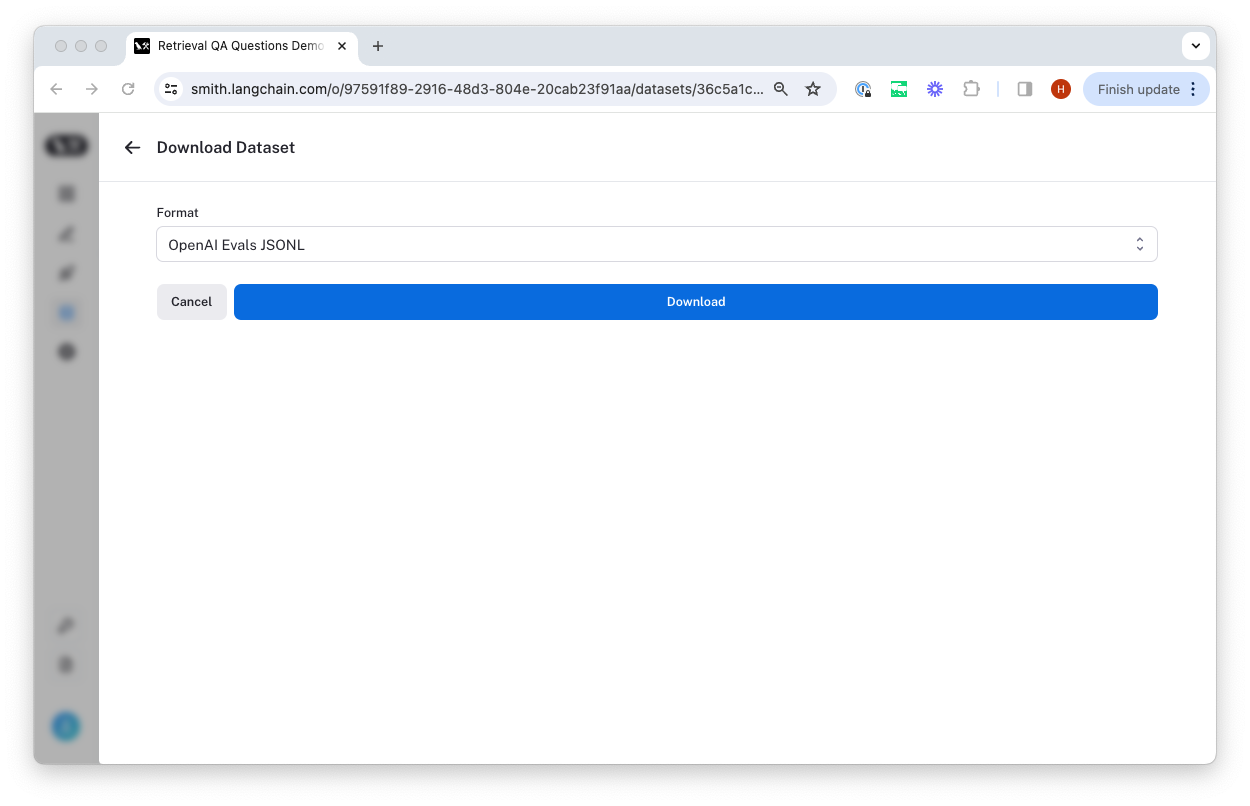
This will open a modal where you can select the format you want to export to.
How to manage datasets programmatically
You can create a dataset from existing runs or upload a CSV file (or pandas dataframe in python).
Once you have a dataset created, you can continue to add new runs to it as examples. We recommend that you organize datasets to target a single "task", usually served by a single chain or LLM. For more discussions on datasets and evaluations, check out the recommendations.
Create from list of values
The most flexible way to make a dataset using the client is by creating examples from a list of inputs and optional outputs. Below is an example.
Note that you can add arbitrary metadata to each example, such as a note or a source. The metadata is stored as a dictionary.
- Python
- TypeScript
from langsmith import Client
example_inputs = [
("What is the largest mammal?", "The blue whale"),
("What do mammals and birds have in common?", "They are both warm-blooded"),
("What are reptiles known for?", "Having scales"),
("What's the main characteristic of amphibians?", "They live both in water and on land"),
]
client = Client()
dataset_name = "Elementary Animal Questions"
# Storing inputs in a dataset lets us
# run chains and LLMs over a shared set of examples.
dataset = client.create_dataset(
dataset_name=dataset_name, description="Questions and answers about animal phylogenetics.",
)
for input_prompt, output_answer in example_inputs:
client.create_example(
inputs={"question": input_prompt},
outputs={"answer": output_answer},
metadata={"source": "Wikipedia"},
dataset_id=dataset.id,
)
import { Client } from "langsmith";
const client = new Client({
// apiUrl: "https://api.langchain.com", // Defaults to the LANGCHAIN_ENDPOINT env var
// apiKey: "my_api_key", // Defaults to the LANGCHAIN_API_KEY env var
/* callerOptions: {
maxConcurrency?: Infinity; // Maximum number of concurrent requests to make
maxRetries?: 6; // Maximum number of retries to make
}*/
});
const exampleInputs: [string, string][] = [
["What is the largest mammal?", "The blue whale"],
["What do mammals and birds have in common?", "They are both warm-blooded"],
["What are reptiles known for?", "Having scales"],
["What's the main characteristic of amphibians?", "They live both in water and on land"],
];
const datasetName = "Elementary Animal Questions";
// Storing inputs in a dataset lets us
// run chains and LLMs over a shared set of examples.
const dataset = await client.createDataset(datasetName, {
description: "Questions and answers about animal phylogenetics",
});
for (const [inputPrompt, outputAnswer] of exampleInputs) {
await client.createExample(
{ question: inputPrompt },
{ answer: outputAnswer },
{
datasetId: dataset.id,
metadata: { source: "Wikipedia" },
}
);
}
Create from existing runs
To create datasets from existing runs, you can use the same approach. Below is an example:
- Python
- TypeScript
from langsmith import Client
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-LANGSMITH-API-KEY>"
client = Client()
dataset_name = "Example Dataset"
# Filter runs to add to the dataset
runs = client.list_runs(
project_name="my_project",
execution_order=1,
error=False,
)
dataset = client.create_dataset(dataset_name, description="An example dataset")
for run in runs:
client.create_example(
inputs=run.inputs,
outputs=run.outputs,
dataset_id=dataset.id,
)
import { Client, Run } from "langsmith";
const client = new Client({
// apiUrl: "https://api.langchain.com", // Defaults to the LANGCHAIN_ENDPOINT env var
// apiKey: "my_api_key", // Defaults to the LANGCHAIN_API_KEY env var
/* callerOptions: {
maxConcurrency?: Infinity; // Maximum number of concurrent requests to make
maxRetries?: 6; // Maximum number of retries to make
}*/
});
const datasetName = "Example Dataset";
// Filter runs to add to the dataset
const runs: Run[] = [];
for await (const run of client.listRuns({
projectName: "my_project",
executionOrder: 1,
error: false,
})) {
runs.push(run);
}
const dataset = await client.createDataset(datasetName, {
description: "An example dataset",
dataType: "kv",
});
for (const run of runs) {
await client.createExample(run.inputs, run.outputs ?? {}, {
datasetId: dataset.id,
});
}
Create dataset from CSV
In this section, we will demonstrate how you can create a dataset by uploading a CSV file.
First, ensure your CSV file is properly formatted with columns that represent your input and output keys. These keys will be utilized to map your data properly during the upload. You can specify an optional name and description for your dataset. Otherwise, the file name will be used as the dataset name and no description will be provided.
- Python
- TypeScript
from langsmith import Client
import os
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-LANGSMITH-API-KEY>"
client = Client()
csv_file = 'path/to/your/csvfile.csv'
input_keys = ['column1', 'column2'] # replace with your input column names
output_keys = ['output1', 'output2'] # replace with your output column names
dataset = client.upload_csv(
csv_file=csv_file,
input_keys=input_keys,
output_keys=output_keys,
name="My CSV Dataset",
description="Dataset created from a CSV file"
data_type="kv"
)
import { Client } from "langsmith";
const client = new Client();
const csvFile = 'path/to/your/csvfile.csv';
const inputKeys = ['column1', 'column2']; // replace with your input column names
const outputKeys = ['output1', 'output2']; // replace with your output column names
const dataset = await client.uploadCsv({
csvFile: csvFile,
fileName: "My CSV Dataset",
inputKeys: inputKeys,
outputKeys: outputKeys,
description: "Dataset created from a CSV file",
dataType: "kv"
});
Create dataset from pandas dataframe
The python client offers an additional convenience method to upload a dataset from a pandas dataframe.
from langsmith import Client
import os
import pandas as pd
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-LANGSMITH-API-KEY>"
client = Client()
df = pd.read_parquet('path/to/your/myfile.parquet')
input_keys = ['column1', 'column2'] # replace with your input column names
output_keys = ['output1', 'output2'] # replace with your output column names
dataset = client.upload_dataframe(
df=df,
input_keys=input_keys,
output_keys=output_keys,
name="My Parquet Dataset",
description="Dataset created from a parquet file",
data_type="kv" # The default
)
List datasets from the client
You can programmatically fetch the datasets from LangSmith using the list_datasets method in the client. Below are some common examples:
Query all datasets
- Python
- TypeScript
datasets = client.list_datasets()
const datasets = await client.listDatasets();
List datasets by name
If you want to search by the exact name, you can do the following:
- Python
- TypeScript
datasets = client.list_datasets(dataset_name="My Test Dataset 1")
const datasets = await client.listDatasets({datasetName: "My Test Dataset 1"});
If you want to do a case-invariant substring search, try the following:
- Python
- TypeScript
datasets = client.list_datasets(dataset_name_contains="some substring")
const datasets = await client.listDatasets({datasetNameContains: "some substring"});
List datasets by type
You can filter datasets by type. Below is an example querying for chat datasets.
- Python
- TypeScript
datasets = client.list_datasets(data_type="chat")
const datasets = await client.listDatasets({dataType: "chat"});
List Examples from the client
Once you have a dataset created, you may want to download the examples. You can fetch dataset examples using the list_examples method on the LangSmith client. Below are some common calls:
List all examples for a dataset
You can filter by dataset ID:
- Python
- TypeScript
examples = client.list_examples(dataset_id="c9ace0d8-a82c-4b6c-13d2-83401d68e9ab")
const examples = await client.listExamples({datasetId: "c9ace0d8-a82c-4b6c-13d2-83401d68e9ab"});
Or you can filter by dataset name (this must exactly match the dataset name you want to query)
- Python
- TypeScript
examples = client.list_examples(dataset_name="My Test Dataset")
const examples = await client.listExamples({datasetName: "My test Dataset"});
List examples by id
You can also list multiple examples all by ID.
- Python
- TypeScript
example_ids = [
'734fc6a0-c187-4266-9721-90b7a025751a',
'd6b4c1b9-6160-4d63-9b61-b034c585074f',
'4d31df4e-f9c3-4a6e-8b6c-65701c2fed13',
]
examples = client.list_examples(example_ids=example_ids)
const exampleIds = [
"734fc6a0-c187-4266-9721-90b7a025751a",
"d6b4c1b9-6160-4d63-9b61-b034c585074f",
"4d31df4e-f9c3-4a6e-8b6c-65701c2fed13",
];
const examples = await client.listExamples({exampleIds: exampleIds});