Annotate code for tracing
If you've decided you no longer want to trace your runs, you can remove the LANGSMITH_TRACING environment variable.
Note that this does not affect the RunTree objects or API users, as these are meant to be low-level and not affected by the tracing toggle.
There are several ways to log traces to LangSmith.
If you are using LangChain (either Python or JS/TS), you can skip this section and go directly to the LangChain-specific instructions.
Use @traceable / traceable
LangSmith makes it easy to log traces with minimal changes to your existing code with the @traceable decorator in Python and traceable function in TypeScript.
The LANGSMITH_TRACING environment variable must be set to 'true' in order for traces to be logged to LangSmith, even when using @traceable or traceable. This allows you to toggle tracing on and off without changing your code.
Additionally, you will need to set the LANGSMITH_API_KEY environment variable to your API key (see Setup for more information).
By default, the traces will be logged to a project named default.
To log traces to a different project, see this section.
- Python
- TypeScript
The @traceable decorator is a simple way to log traces from the LangSmith Python SDK. Simply decorate any function with @traceable.
from langsmith import traceable
from openai import Client
openai = Client()
@traceable
def format_prompt(subject):
return [
{
"role": "system",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": f"What's a good name for a store that sells {subject}?"
}
]
@traceable(run_type="llm")
def invoke_llm(messages):
return openai.chat.completions.create(
messages=messages, model="gpt-4o-mini", temperature=0
)
@traceable
def parse_output(response):
return response.choices[0].message.content
@traceable
def run_pipeline():
messages = format_prompt("colorful socks")
response = invoke_llm(messages)
return parse_output(response)
run_pipeline()
The traceable function is a simple way to log traces from the LangSmith TypeScript SDK. Simply wrap any function with traceable.
Note that when wrapping a sync function with traceable, (e.g. formatPrompt in the example below), you should use the await keyword when calling it to ensure the trace is logged correctly.
import { traceable } from "langsmith/traceable";
import OpenAI from "openai";
const openai = new OpenAI();
const formatPrompt = traceable(
(subject: string) => {
return [
{
role: "system" as const,
content: "You are a helpful assistant.",
},
{
role: "user" as const,
content: `What's a good name for a store that sells ${subject}?`,
},
];
},
{ name: "formatPrompt" }
);
const invokeLLM = traceable(
async ({ messages }: { messages: { role: string; content: string }[] }) => {
return openai.chat.completions.create({
model: "gpt-4o-mini",
messages: messages,
temperature: 0,
});
},
{ run_type: "llm", name: "invokeLLM" }
);
const parseOutput = traceable(
(response: any) => {
return response.choices[0].message.content;
},
{ name: "parseOutput" }
);
const runPipeline = traceable(
async () => {
const messages = await formatPrompt("colorful socks");
const response = await invokeLLM({ messages });
return parseOutput(response);
},
{ name: "runPipeline" }
);
await runPipeline();
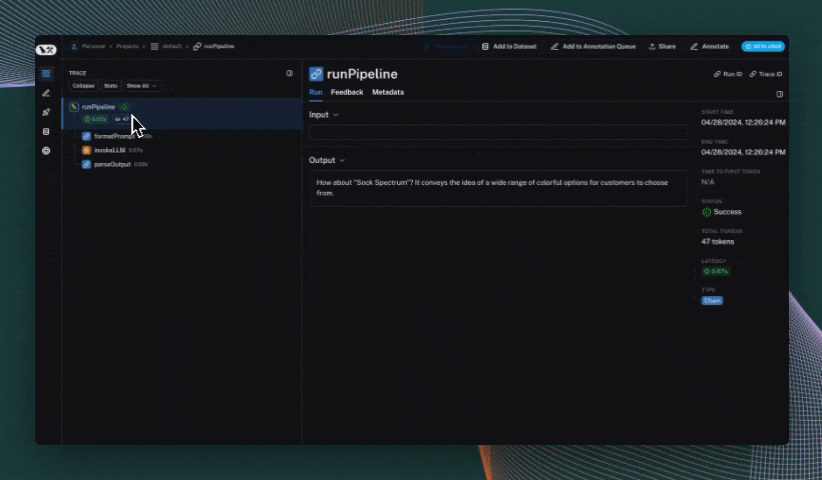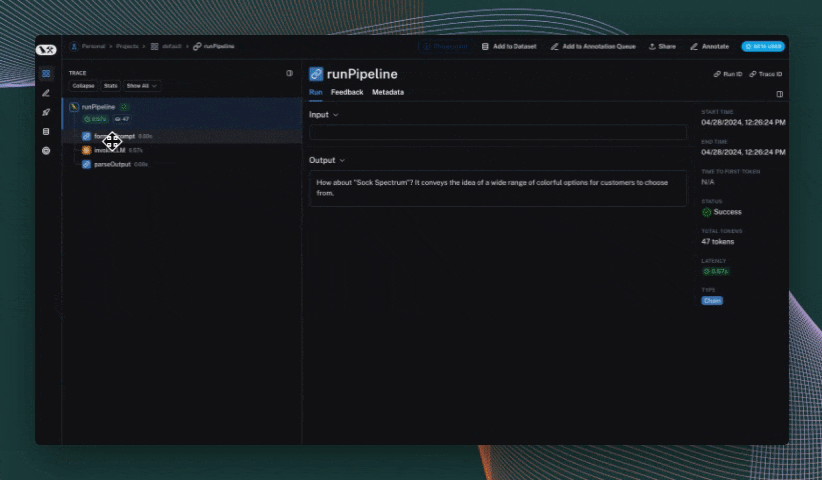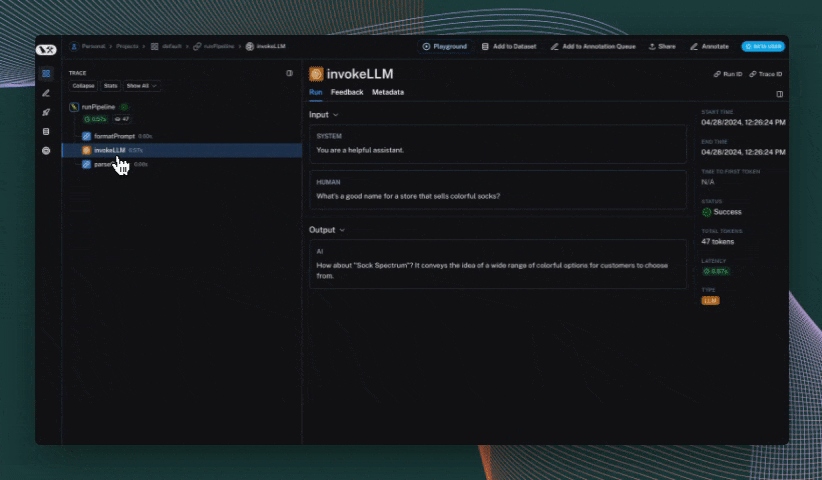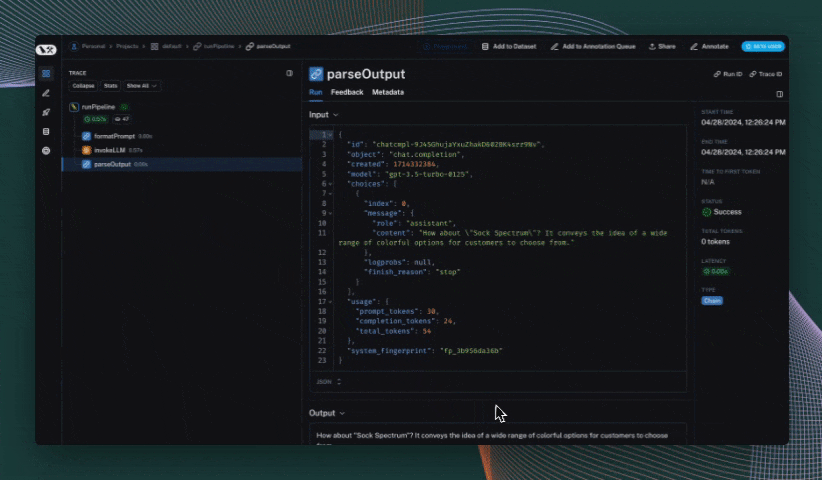
Use the trace context manager (Python only)
In Python, you can use the trace context manager to log traces to LangSmith. This is useful in situations where:
- You want to log traces for a specific block of code.
- You want control over the inputs, outputs, and other attributes of the trace.
- It is not feasible to use a decorator or wrapper.
- Any or all of the above.
The context manager integrates seamlessly with the traceable decorator and wrap_openai wrapper, so you can use them together in the same application.
import openai
import langsmith as ls
from langsmith.wrappers import wrap_openai
client = wrap_openai(openai.Client())
@ls.traceable(run_type="tool", name="Retrieve Context")
def my_tool(question: str) -> str:
return "During this morning's meeting, we solved all world conflict."
def chat_pipeline(question: str):
context = my_tool(question)
messages = [
{ "role": "system", "content": "You are a helpful assistant. Please respond to the user's request only based on the given context." },
{ "role": "user", "content": f"Question: {question}\nContext: {context}"}
]
chat_completion = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return chat_completion.choices[0].message.content
app_inputs = {"input": "Can you summarize this morning's meetings?"}
with ls.trace("Chat Pipeline", "chain", project_name="my_test", inputs=app_inputs) as rt:
output = chat_pipeline("Can you summarize this morning's meetings?")
rt.end(outputs={"output": output})
Wrap the OpenAI client
The wrap_openai/wrapOpenAI methods in Python/TypeScript allow you to wrap your OpenAI client in order to automatically log traces -- no decorator or function wrapping required!
Using the wrapper ensures that messages, including tool calls and multimodal content blocks will be rendered nicely in LangSmith.
Also note that the wrapper works seamlessly with the @traceable decorator or traceable function and you can use both in the same application.
The LANGSMITH_TRACING environment variable must be set to 'true' in order for traces to be logged to LangSmith, even when using wrap_openai or wrapOpenAI. This allows you to toggle tracing on and off without changing your code.
Additionally, you will need to set the LANGSMITH_API_KEY environment variable to your API key (see Setup for more information).
By default, the traces will be logged to a project named default.
To log traces to a different project, see this section.
- Python
- TypeScript
import openai
from langsmith import traceable
from langsmith.wrappers import wrap_openai
client = wrap_openai(openai.Client())
@traceable(run_type="tool", name="Retrieve Context")
def my_tool(question: str) -> str:
return "During this morning's meeting, we solved all world conflict."
@traceable(name="Chat Pipeline")
def chat_pipeline(question: str):
context = my_tool(question)
messages = [
{ "role": "system", "content": "You are a helpful assistant. Please respond to the user's request only based on the given context." },
{ "role": "user", "content": f"Question: {question}\nContext: {context}"}
]
chat_completion = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
return chat_completion.choices[0].message.content
chat_pipeline("Can you summarize this morning's meetings?")
import OpenAI from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers";
const client = wrapOpenAI(new OpenAI());
const myTool = traceable(async (question: string) => {
return "During this morning's meeting, we solved all world conflict.";
}, { name: "Retrieve Context", run_type: "tool" });
const chatPipeline = traceable(async (question: string) => {
const context = await myTool(question);
const messages = [
{
role: "system",
content:
"You are a helpful assistant. Please respond to the user's request only based on the given context.",
},
{ role: "user", content: `Question: ${question} Context: ${context}` },
];
const chatCompletion = await client.chat.completions.create({
model: "gpt-4o-mini",
messages: messages,
});
return chatCompletion.choices[0].message.content;
}, { name: "Chat Pipeline" });
await chatPipeline("Can you summarize this morning's meetings?");
Wrap the Anthropic client (Python only)
The wrap_anthropic methods in Python allows you to wrap your Anthropic client in order to automatically log traces -- no decorator or function wrapping required!
Using the wrapper ensures that messages, including tool calls and multimodal content blocks will be rendered nicely in LangSmith.
The wrapper works seamlessly with the @traceable decorator or traceable function and you can use both in the same application.
The LANGSMITH_TRACING environment variable must be set to 'true' in order for traces to be logged to LangSmith, even when using wrap_anthropic. This allows you to toggle tracing on and off without changing your code.
Additionally, you will need to set the LANGSMITH_API_KEY environment variable to your API key (see Setup for more information).
By default, the traces will be logged to a project named default.
To log traces to a different project, see this section.
import anthropic
from langsmith import traceable
from langsmith.wrappers import wrap_anthropic
client = wrap_anthropic(anthropic.Anthropic())
# You can also wrap the async client as well
# async_client = wrap_anthropic(anthropic.AsyncAnthropic())
@traceable(run_type="tool", name="Retrieve Context")
def my_tool(question: str) -> str:
return "During this morning's meeting, we solved all world conflict."
@traceable(name="Chat Pipeline")
def chat_pipeline(question: str):
context = my_tool(question)
messages = [
{ "role": "user", "content": f"Question: {question}\\nContext: {context}"}
]
chat_completion = client.messages.create(
model="claude-sonnet-4-20250514",
messages=messages,
max_tokens=3,
system="You are a helpful assistant. Please respond to the user's request only based on the given context."
)
return chat_completion.choices[0].message.content
chat_pipeline("Can you summarize this morning's meetings?")
Use the RunTree API
Another, more explicit way to log traces to LangSmith is via the RunTree API. This API allows you more control over your tracing - you can manually
create runs and children runs to assemble your trace. You still need to set your LANGSMITH_API_KEY, but LANGSMITH_TRACING is not
necessary for this method.
This method is not recommended, as it's easier to make mistakes in propagating trace context.
- Python
- TypeScript
import openai
from langsmith.run_trees import RunTree
# This can be a user input to your app
question = "Can you summarize this morning's meetings?"
# Create a top-level run
pipeline = RunTree(
name="Chat Pipeline",
run_type="chain",
inputs={"question": question}
)
pipeline.post()
# This can be retrieved in a retrieval step
context = "During this morning's meeting, we solved all world conflict."
messages = [
{ "role": "system", "content": "You are a helpful assistant. Please respond to the user's request only based on the given context." },
{ "role": "user", "content": f"Question: {question}\nContext: {context}"}
]
# Create a child run
child_llm_run = pipeline.create_child(
name="OpenAI Call",
run_type="llm",
inputs={"messages": messages},
)
child_llm_run.post()
# Generate a completion
client = openai.Client()
chat_completion = client.chat.completions.create(
model="gpt-4o-mini", messages=messages
)
# End the runs and log them
child_llm_run.end(outputs=chat_completion)
child_llm_run.patch()
pipeline.end(outputs={"answer": chat_completion.choices[0].message.content})
pipeline.patch()
import OpenAI from "openai";
import { RunTree } from "langsmith";
// This can be a user input to your app
const question = "Can you summarize this morning's meetings?";
const pipeline = new RunTree({
name: "Chat Pipeline",
run_type: "chain",
inputs: { question }
});
await pipeline.postRun();
// This can be retrieved in a retrieval step
const context = "During this morning's meeting, we solved all world conflict.";
const messages = [
{ role: "system", content: "You are a helpful assistant. Please respond to the user's request only based on the given context." },
{ role: "user", content: `Question: ${question}
Context: ${context}` }
];
// Create a child run
const childRun = await pipeline.createChild({
name: "OpenAI Call",
run_type: "llm",
inputs: { messages },
});
await childRun.postRun();
// Generate a completion
const client = new OpenAI();
const chatCompletion = await client.chat.completions.create({
model: "gpt-4o-mini",
messages: messages,
});
// End the runs and log them
childRun.end(chatCompletion);
await childRun.patchRun();
pipeline.end({ outputs: { answer: chatCompletion.choices[0].message.content } });
await pipeline.patchRun();
Example usage
You can extend the utilities above to conveniently trace any code. Below are some example extensions:
Trace any public method in a class:
from typing import Any, Callable, Type, TypeVar
T = TypeVar("T")
def traceable_cls(cls: Type[T]) -> Type[T]:
"""Instrument all public methods in a class."""
def wrap_method(name: str, method: Any) -> Any:
if callable(method) and not name.startswith("__"):
return traceable(name=f"{cls.__name__}.{name}")(method)
return method
# Handle __dict__ case
for name in dir(cls):
if not name.startswith("_"):
try:
method = getattr(cls, name)
setattr(cls, name, wrap_method(name, method))
except AttributeError:
# Skip attributes that can't be set (e.g., some descriptors)
pass
# Handle __slots__ case
if hasattr(cls, "__slots__"):
for slot in cls.__slots__: # type: ignore[attr-defined]
if not slot.startswith("__"):
try:
method = getattr(cls, slot)
setattr(cls, slot, wrap_method(slot, method))
except AttributeError:
# Skip slots that don't have a value yet
pass
return cls
@traceable_cls
class MyClass:
def __init__(self, some_val: int):
self.some_val = some_val
def combine(self, other_val: int):
return self.some_val + other_val
# See trace: https://smith.langchain.com/public/882f9ecf-5057-426a-ae98-0edf84fdcaf9/r
MyClass(13).combine(29)
Ensure all traces are submitted before exiting
LangSmith's tracing is done in a background thread to avoid obstructing your production application. This means that your process may end before all traces are successfully posted to LangSmith. Here are some options for ensuring all traces are submitted before exiting your application.
Using the LangSmith SDK
If you are using the LangSmith SDK standalone, you can use the flush method before exit:
- Python
- TypeScript
from langsmith import Client
client = Client()
@traceable(client=client)
async def my_traced_func():
# Your code here...
pass
try:
await my_traced_func()
finally:
await client.flush()
import { Client } from "langsmith";
const langsmithClient = new Client({});
const myTracedFunc = traceable(
async () => {
// Your code here...
},
{ client: langsmithClient }
);
try {
await myTracedFunc();
} finally {
await langsmithClient.flush();
}
Using LangChain
If you are using LangChain, please refer to our LangChain tracing guide.
If you prefer a video tutorial, check out the Tracing Basics video from the Introduction to LangSmith Course.