Get started with LangSmith
LangSmith is a platform for building production-grade LLM applications. It allows you to closely monitor and evaluate your application, so you can ship quickly and with confidence.
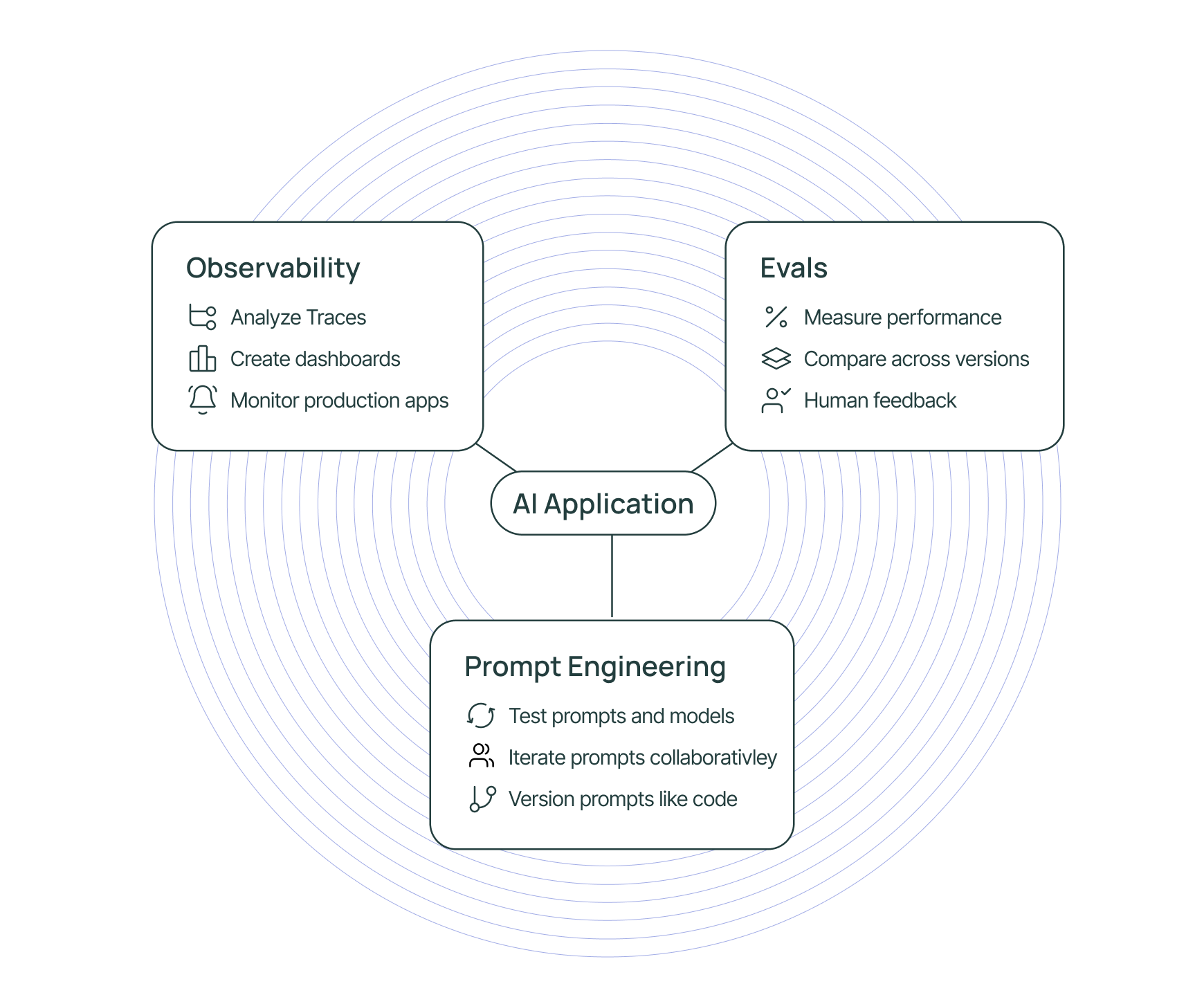
Observability
Analyze traces in LangSmith and configure metrics, dashboards, alerts based on these.
Evals
Evaluate your application over production traffic — score application performance and get human feedback on your data.
Prompt Engineering
Iterate on prompts, with automatic version control and collaboration features.
LangSmith is framework-agnostic — it can be used with or without LangChain's open source frameworks langchain and langgraph.
If you are using either of these, you can enable LangSmith tracing with a single environment variable. For more see the how-to guide for setting up LangSmith with LangChain or setting up LangSmith with LangGraph.
Observability
Observability is important for any software application, but especially so for LLM applications. LLMs are non-deterministic by nature, meaning they can produce unexpected results. This makes them trickier than normal to debug.
This is where LangSmith can help! LangSmith has LLM-native observability, allowing you to get meaningful insights from your application. LangSmith’s observability features have you covered throughout all stages of application development - from prototyping, to beta testing, to production.
- Get started by adding tracing to your application.
- Create dashboards to view key metrics like RPS, error rates and costs.
Evals
The quality and development speed of AI applications depends on high-quality evaluation datasets and metrics to test and optimize your applications on. The LangSmith SDK and UI make building and running high-quality evaluations easy.
- Get started by creating your first evaluation.
- Quickly assess the performance of your application using our off-the-shelf evaluators as a starting point.
- Analyze results of evaluations in the LangSmith UI and compare results over time.
- Easily collect human feedback on your data to improve your application.
Prompt Engineering
While traditional software applications are built by writing code, AI applications involve writing prompts to instruct the LLM on what to do. LangSmith provides a set of tools designed to enable and facilitate prompt engineering to help you find the perfect prompt for your application.
- Get started by creating your first prompt.
- Iterate on models and prompts using the Playground.
- Manage prompts programmatically in your application.